Diagnosing LLM Failures Before Switching Techniques
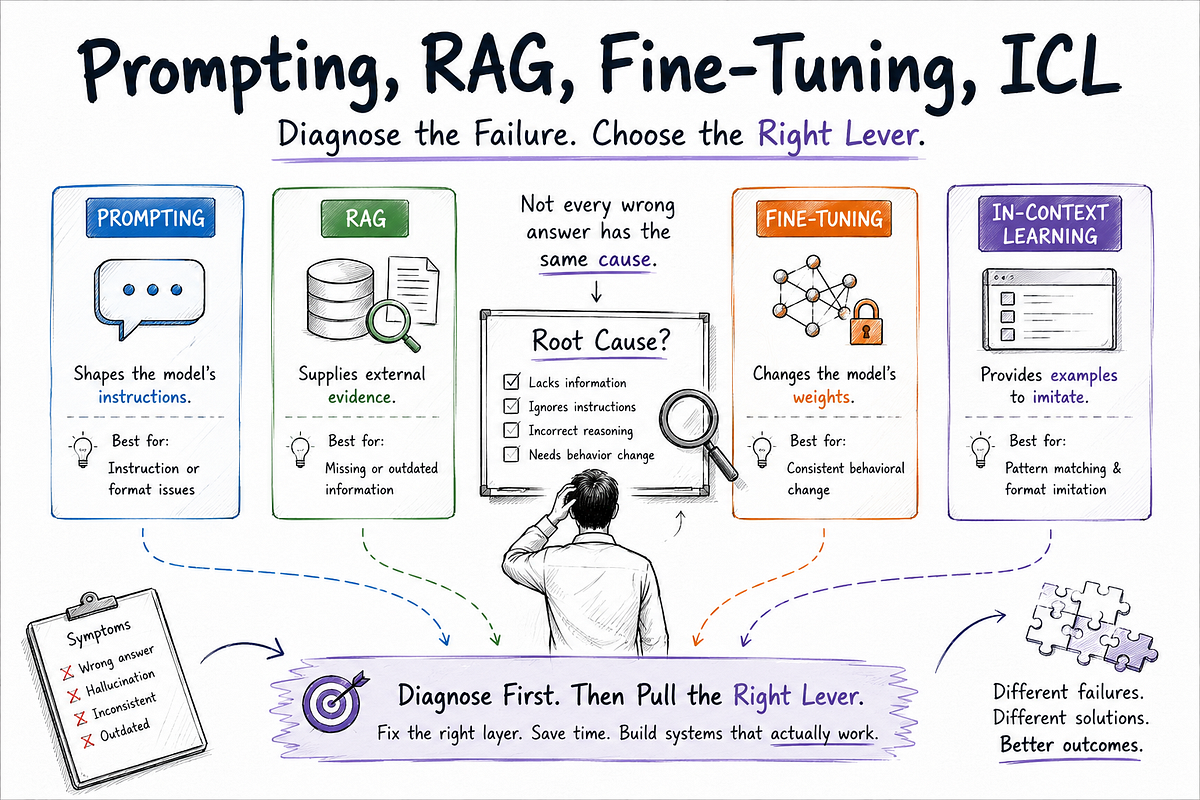
Towards AI published a July 4, 2026 practitioner piece arguing that LLM failures are usually fixed by diagnosing the failed system layer before switching techniques. The article frames prompting, RAG, fine-tuning, and in-context learning as remediation levers, not interchangeable upgrades. For teams running support bots, copilots, or retrieval systems, the useful lesson is operational: isolate whether the error came from data quality, retrieval relevance, prompt structure, model capability, or downstream business logic before adding cost or complexity. Because the source is a single practical essay rather than a benchmark or peer-reviewed result, the finding should be treated as engineering guidance, not a universal claim.
Production LLM teams waste the least effort when failures are diagnosable before they are expensive. The practical value of the Towards AI piece is its reminder that a failed response is usually evidence about a system layer, not an automatic reason to jump from prompting to RAG, fine-tuning, or another larger intervention.
What happened
Towards AI published a July 4, 2026 essay titled "Prompting, RAG, Fine-Tuning, ICL" that argues many AI failures are fixed by identifying which layer failed. The article uses a customer-support chatbot example to show how teams can chase multiple techniques before isolating the actual failure mode.
Technical context
The remediation options are different engineering tools. Prompt changes can improve instruction following, RAG can improve grounding, fine-tuning can adapt behavior to task patterns, and in-context learning can guide a model with examples. None of those fixes substitutes for testing whether the data, retrieval, prompt, model capability, or application logic produced the error.
For practitioners
A useful incident workflow is to reproduce the bad output, freeze the input, inspect retrieved evidence, test a minimal prompt, compare model behavior, and then check downstream business rules. That sequence keeps teams from adding systems that mask the symptom while leaving the root cause in place.
What to watch
The source is a single practitioner essay, so LDS should not frame it as research consensus. The lasting value is operational: teams that turn LLM failures into repeatable diagnostics can cut remediation cost and build clearer post-incident evidence.
Key Points
- 1Failure diagnosis should isolate data, retrieval, prompt, model, and application layers before teams choose a remediation technique.
- 2Treating RAG, fine-tuning, prompting, and ICL as interchangeable fixes can add cost without removing the root cause.
- 3Production LLM teams benefit from reproducible tests that map symptoms to the specific layer that failed.
Scoring Rationale
The article offers useful production guidance for teams operating LLM applications, especially around failure diagnosis and remediation choice. It is still a single practitioner essay rather than new research or a platform change, so the score should stay in the moderate-practical range.
Sources
Public references used for this report.
Practice with real FinTech & Trading data
90 SQL & Python problems · 15 industry datasets
250 free problems · No credit card
See all FinTech & Trading problems


