The through-line across late July and early August 2026 is that top-end capability, self-hostable scale and verifiable evidence are now moving on three separate tracks. OpenAI disclosed on August 1 that an internal version of Astra, which it describes as its next major model, produced ten results in mathematics and theoretical computer science, and it published human-prepared manuscripts, a Lean formalization of each argument and a model narration of the reasoning, estimating the total token cost of finding the ten solutions at roughly $2,000 at Sol API rates. That release shipped inspectable proof artifacts instead of benchmark scores, but OpenAI published no model card, architecture, context-window specification, API details or release date for Astra. In the same three-week window the open-weight tier reached trillion-parameter scale: Moonshot AI published Kimi K3's full weights on July 27, with a model card listing 2.8 trillion total parameters, 104 billion activated, 896 experts with 16 selected per token and a 1,048,576-token context window under the Kimi K3 License, and Simon Willison put the Hugging Face repository at roughly 1.56 TB. Thinking Machines Lab released Inkling on July 15 at 975 billion total and 41 billion active parameters under Apache 2.0, and LG AI Research published K-EXAONE 2.0 on July 31 at 750 billion total and 37 billion active parameters, also Apache 2.0. Weights at that size shift infrastructure, evaluation, security review and monitoring costs onto whoever downloads them; Nature reported that K3's size alone could limit adoption even if its capabilities hold up.
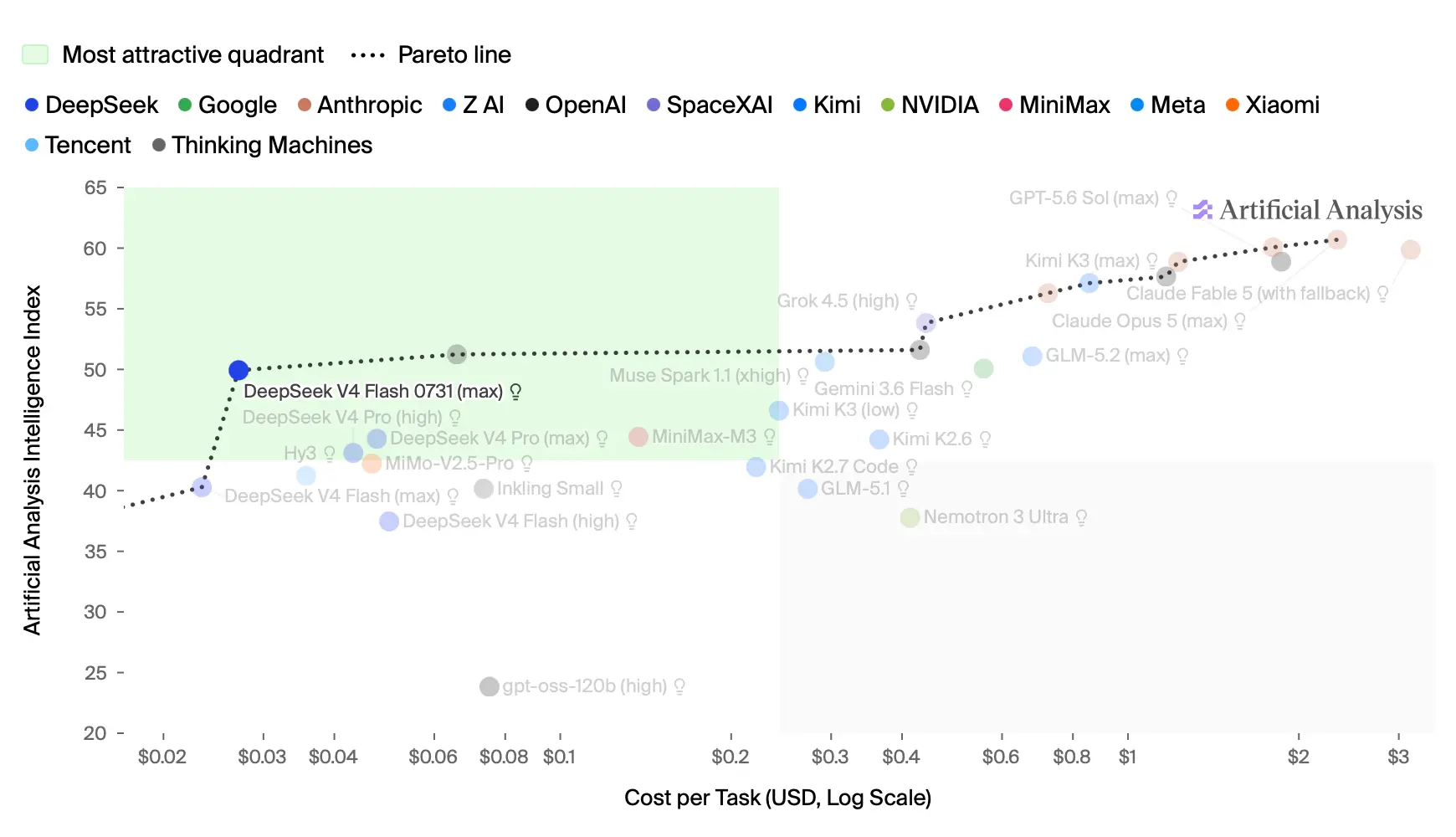
Pricing and serving economics moved in the same direction at the same time. Anthropic released Claude Opus 5 on July 24 at $5 per million input tokens and $25 per million output tokens, matching Opus 4.8's base pricing and half the price of Claude Fable 5, and made it the default for Claude Max. OpenAI then cut GPT-5.6 Terra by 20% and Luna by 80% on July 30, listing Terra at $2 and $12 and Luna at $0.20 and $1.20 per million input and output tokens, and said on July 29 that Sol-assisted production-kernel work had reduced its own end-to-end serving costs by 20% while a Sol-improved speculative-decoding draft model raised token-generation efficiency by more than 15%, both company-reported production measurements with no announced customer price change attached. Cheaper tokens and downloadable weights do not reduce the verification burden, they concentrate it. DeepSeek's July 31 V4-Flash-0731 release is the clearest example: its own model card reports 82.7 on Terminal Bench 2.1 and 54.4 on DeepSWE using an unreleased minimal mode of DeepSeek Harness and internal test sets, while Artificial Analysis independently scored the model 50 on its Intelligence Index, up from 40, and found its hallucination rate falling 11 points to 84% with accuracy unchanged at 37%. Arena, whose factuality leaderboard rests on more than 2 million labeled claims from real conversations weighted 25% factuality against 75% human preference, told Lets Data Science that OpenAI is the only provider consistently improving factuality over an extended period and that most open-source models lose ground once factual accuracy is counted. For anyone building or buying, the operative response is unchanged and more urgent: pin model versions, reproduce vendor benchmarks inside your own harness, and price workloads on measured utilization rather than list rates.



 +2
+2