Tokens Define Model Cost and Context Limits
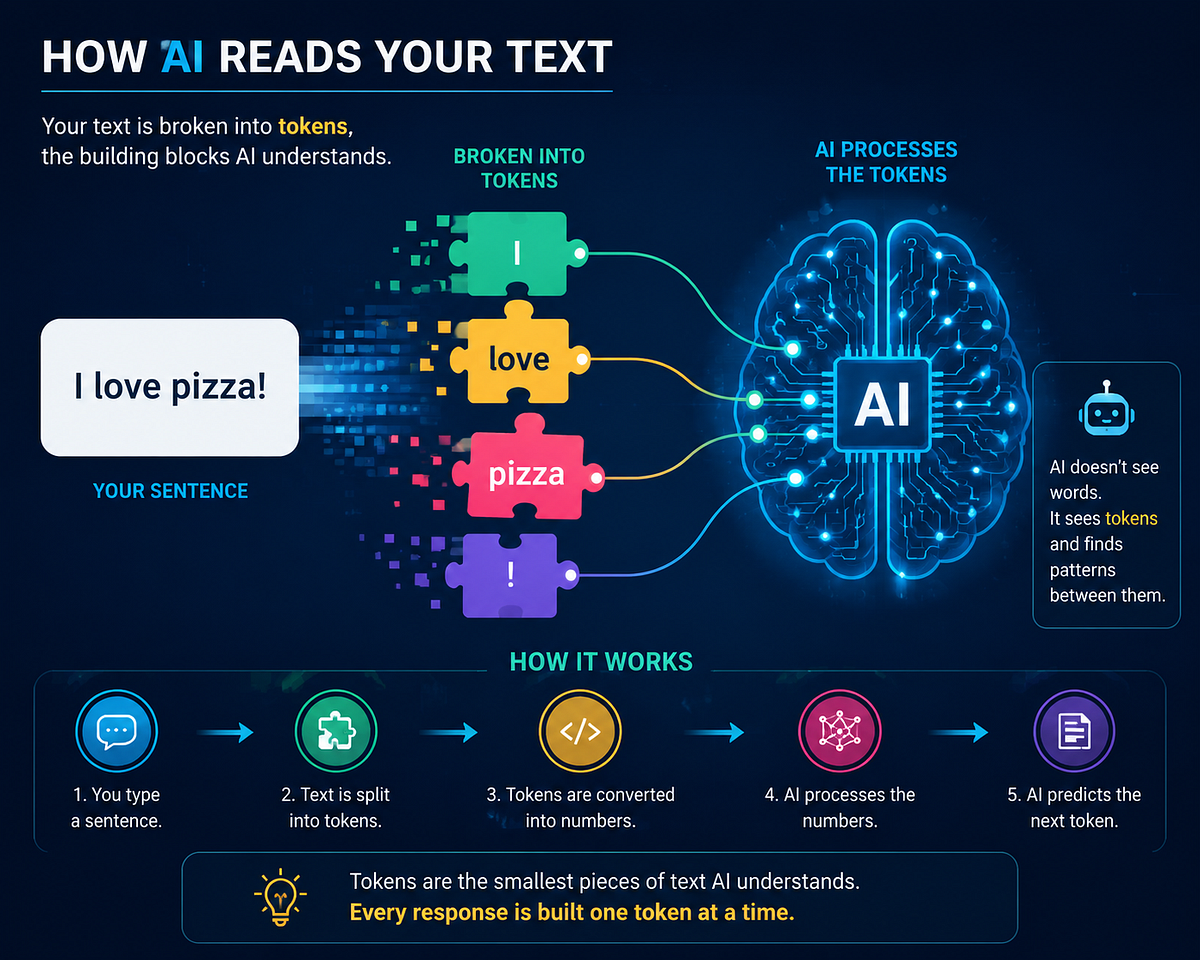
Large language models like ChatGPT process text as tokens, not words, a distinction a July 2026 TowardsAI explainer says determines model cost, context-window limits, and prompt behavior. According to OpenAI's own token documentation, English text runs about one token per four characters, so a token can be a whole word, a word fragment, punctuation, a number, or an emoji. For practitioners, this means API billing and context-window budgets are set by token counts, not word counts, and non-English or code-heavy text can consume tokens far faster than plain English. The piece illustrates the idea with a LEGO-brick analogy, showing how a sentence like "Machine learning is amazing." splits into reusable subword pieces so models can handle rare or unseen words without exploding vocabulary size.
For ML engineers and data scientists, tokens are the operational unit that ties together preprocessing, context-window budgeting, and inference cost, a link that word-count-based estimates of prompt size routinely miss. A TowardsAI explainer published July 3, 2026 breaks down how large language models split text into tokens rather than words, a distinction that directly affects billing and prompt design on nearly every commercial LLM API.
What happened
The TowardsAI piece, "What Is a Token? ChatGPT's Smallest Building Block Explained Simply," describes a token as any small chunk of text - a whole word, a subword fragment, punctuation, a number, a space, a symbol, or an emoji - that a language model treats as its smallest unit of input. It uses a LEGO-brick analogy and a worked example, splitting "Machine learning is amazing." into subword pieces such as [Machine] [learn] [ing] [is] [amaz] [ing] [.], to show how models reuse common subword fragments instead of memorizing whole words.
Technical context
The explainer's description matches how production tokenizers work. According to OpenAI's own token documentation, English text averages roughly one token per four characters, and rules of thumb like "100 tokens is about 75 words" underpin how API usage and cost get measured. Most modern transformer tokenizers, including the byte-pair encoding (BPE) family used by GPT- and Llama-class models, build a vocabulary from individual characters and iteratively merge the most frequent adjacent pairs, per Hugging Face's tokenizer documentation, which is why common words stay whole while rare words split into several subword tokens.
For practitioners
Token counts, not word counts, set the real budget for prompt length, retrieval context, and per-request cost. Teams should measure actual token counts on their own data, especially non-English text, code, or emoji-heavy input, which tokenize less efficiently than plain English, rather than estimating from word counts. The same token-to-character ratio explains why a context window advertised in tokens can hold noticeably less usable text than expected once formatting, code, or non-English strings are included.
What to watch
Tokenization stays mostly invisible until a bill or a context-window error appears, so teams building RAG pipelines or long-context applications should benchmark tokenizer behavior on their own real inputs early rather than assume uniform token-to-word ratios across languages and content types.
Key Points
- 1Large language models process input as tokens, not words, where a token can be a whole word, subword, punctuation mark, or symbol.
- 2Modern tokenizers use byte-pair encoding to build compact vocabularies, so common words stay whole while rare words split into subword pieces.
- 3Because API billing and context windows are measured in tokens, practitioners should measure real token counts on their own data rather than word counts.
Scoring Rationale
Educational explainer of an already well-documented concept (tokenization) rather than a new model, finding, or product launch; useful practitioner primer but not novel research or news, so it sits in the minor tier rather than the prior solid-tier score. Kept above the visibility floor because the underlying content is accurate and now corroborated by official OpenAI and Hugging Face documentation.
Sources
Primary source and supporting public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
