Analysisquantizationllmqwen 3.5llama.cpp
Quantization Reveals Outliers Impacting LLM Accuracy
8.1
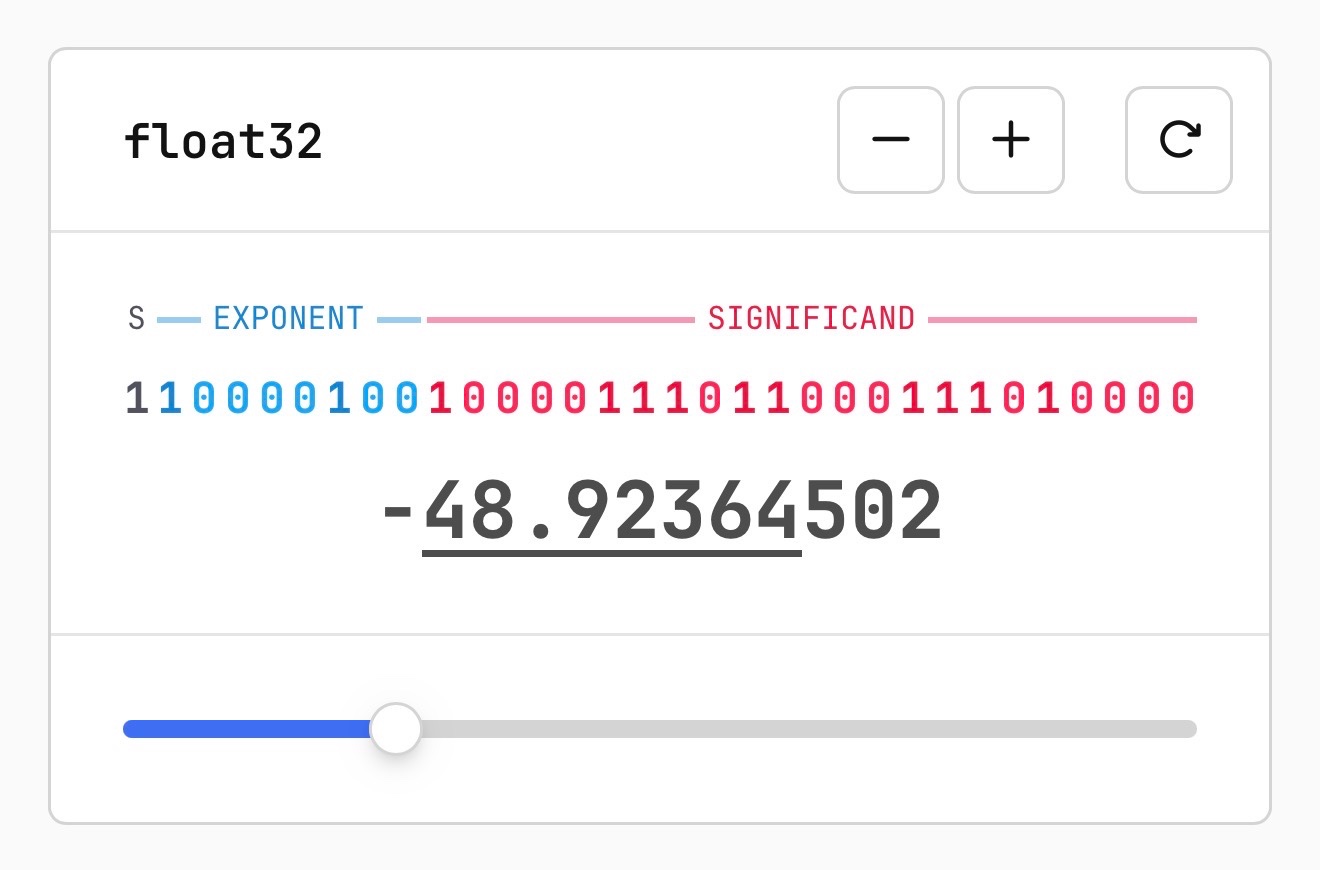
On March 26, 2026, Sam Rose published an interactive essay explaining how quantization of large language models works, including a visual explanation of floating-point representation and the role of rare 'outlier' weights. He documents strategies to preserve these outliers (e.g., leave unquantized or store separately) and benchmarks Qwen 3.5 9B with llama.cpp and GPQA, finding 16→8-bit retains near-original quality while 4-bit yields about 90%.
Key Points
- 1Describes outlier float 'super weights' in LLMs that can critically affect model outputs
- 2Explains preservation methods since outliers significantly influence model quality and quantization fidelity
- 3Shows benchmarks on Qwen 3.5 9B: 16→8-bit near-original quality, 4-bit around 90% accuracy
Scoring Rationale
Practical, industry-wide benchmarks and novel outlier emphasis justify score; limited by single-author blog and non-peer-reviewed format.
Sources
Public references used for this report.
Practice with real Logistics & Shipping data
90 SQL & Python problems · 15 industry datasets
Used by DS/ML engineers at top companies
High-Value Overnight OrdersEasyDelivered International ShipmentsMediumOn-Time Delivery Rate by CarrierHard
250 free problems · No credit card
See all Logistics & Shipping problems

