Developers Use LLMs to Draft Blog Posts
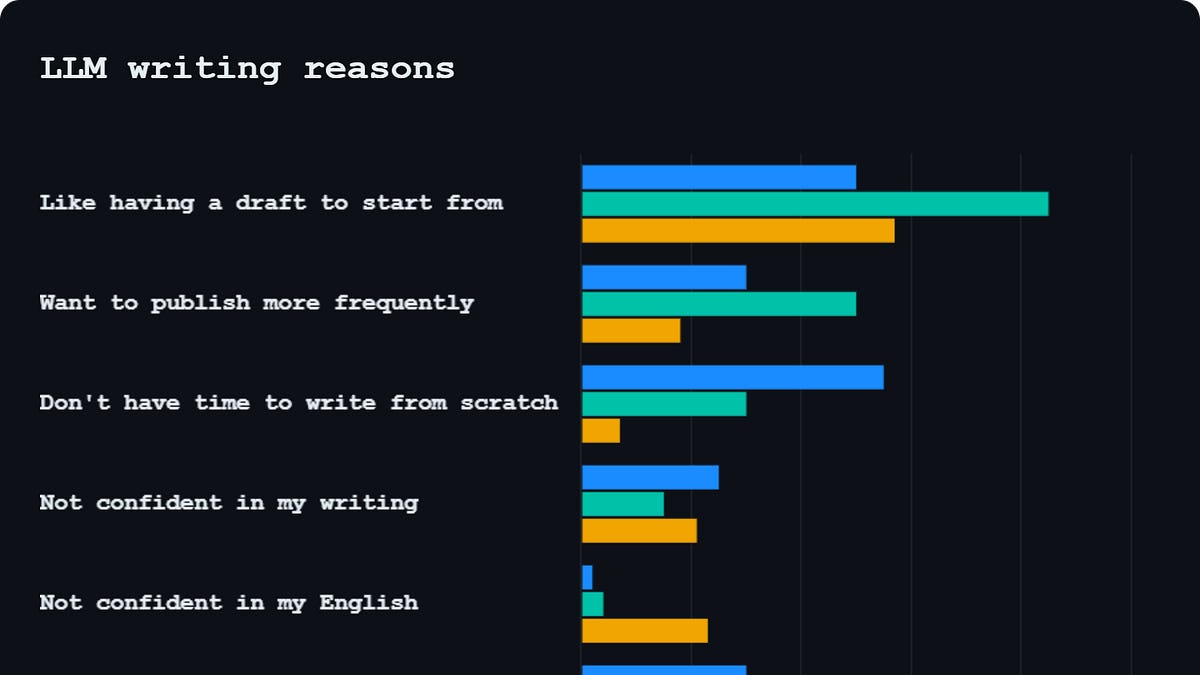
The Substack publication Write That Blog published a June 9, 2026 report based on an anonymous, self-selected survey of 181 developers recruited via X, Bluesky, LinkedIn, Mastodon, and developer Discord servers. According to the report, 40% of respondents who said they "always" use LLMs had never written before and 20% rarely wrote previously; 72% substantially edited generated drafts, 23% rewrote them, only 13% felt LLMs captured their voice, 11% felt LLMs captured their ideas, and 73% did not disclose their LLM use. The author cautions that the sample is self-selected and frames the findings as a snapshot, noting a planned second survey on reader reactions and writers' language backgrounds. The figures come from a single small survey and are not generalizable.
What happened
Write That Blog published a June 9, 2026 report based on an anonymous survey of 181 developers recruited via X, Bluesky, LinkedIn, Mastodon, and developer Discord servers. Per the report, 40% of respondents who categorized themselves as "always-LLM" users had never written before, and 20% rarely wrote prior to using LLMs. The report also states that 72% of those who generated LLM drafts performed substantial editing, 23% totally rewrote drafts, 13% felt LLMs captured their voice, 11% felt LLMs captured their ideas, and 73% did not disclose LLM use.
Editorial analysis - technical context
Industry-pattern observations show these metrics line up with how LLMs are commonly used as ideation and drafting assistants rather than turnkey writers. High post-generation edit rates are consistent with workflows where an LLM supplies structure or phrasing but authors rework content for technical accuracy and personal style. Low perceived voice fidelity is a frequent outcome when models generate first drafts from minimal prompts.
Context and significance
Industry context: For practitioners tracking content provenance and trust, the combination of widespread nondisclosure and low voice fidelity highlights ongoing transparency and attribution gaps around AI-assisted technical writing. The report's sample is small and self-selected, so findings are a snapshot rather than representative prevalence.
What to watch
Observers should look for the planned follow-up survey on reader reactions and writers' language background, larger representative studies measuring nondisclosure rates, and research into tooling that helps preserve author voice while keeping model-assisted productivity gains.
Key Points
- 1A self-selected survey of 181 developers (Write That Blog) found high edit rates, with 72% substantially editing and 23% rewriting LLM-generated drafts.
- 2Only 13% felt LLMs captured their voice and 11% their ideas, while 73% did not disclose LLM use, pointing to transparency gaps in AI-assisted writing.
- 3A notable share of frequent LLM users had little prior writing experience, suggesting LLMs lower the barrier to publishing technical content; the small self-selected sample limits generalizability.
Scoring Rationale
This is on-topic, practitioner-facing data on how developers use LLMs for technical writing, including editing behavior and disclosure rates. The score is modest because it rests on a single, small, self-selected survey from a personal Substack rather than rigorous or representative research, limiting how far the findings generalize.
Sources
Primary source and supporting public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
