Case Studystreaming ingestionhudiflinkdata lake
Uber Re-architects Data Lake Ingestion Platform
8.1
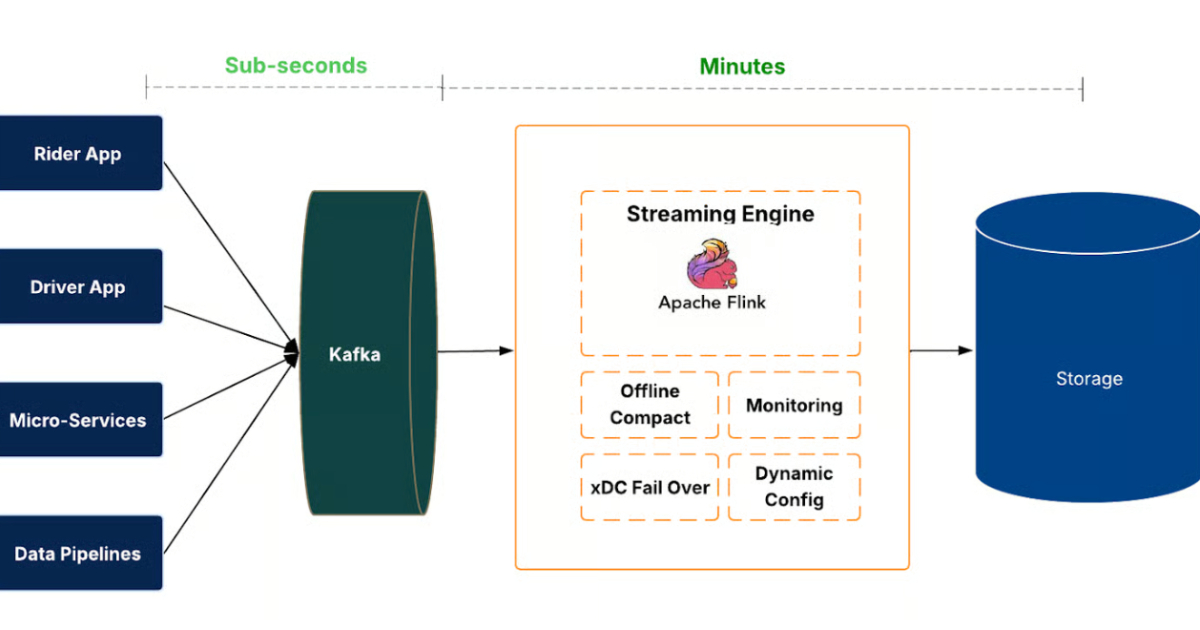
Uber engineers re-architected the company's data lake ingestion platform, replacing scheduled Spark batch jobs with a streaming-first system named IngestionNext. The new pipeline uses Kafka, Flink, and Apache Hudi to reduce ingestion latency from hours to minutes, support thousands of datasets, and cut compute usage by roughly 25%. A control plane, compaction strategies, and failover mechanisms maintain correctness and availability.
Key Points
- 1Implements streaming-first ingestion using Kafka, Flink, and Hudi, cutting ingestion latency from hours to minutes.
- 2Addresses data freshness and correctness with transactional Hudi commits, end-to-end freshness metrics, and regional failover.
- 3Enables faster analytics and ML workflows and reduces compute usage by roughly 25% through continuous scaling.
Scoring Rationale
Strong enterprise engineering with measurable latency and cost benefits; limited novelty beyond established streaming-first patterns.
Practice with real Streaming & Media data
90 SQL & Python problems · 15 industry datasets
Used by DS/ML engineers at top companies
Active Users in Target CountriesEasyHigh-Rated Titles with ReviewsMediumUser Churn Risk AssessmentHard
250 free problems · No credit card
See all Streaming & Media problems


