SentiPulse Open-Sources SentiAvatar 3D Digital Human Framework
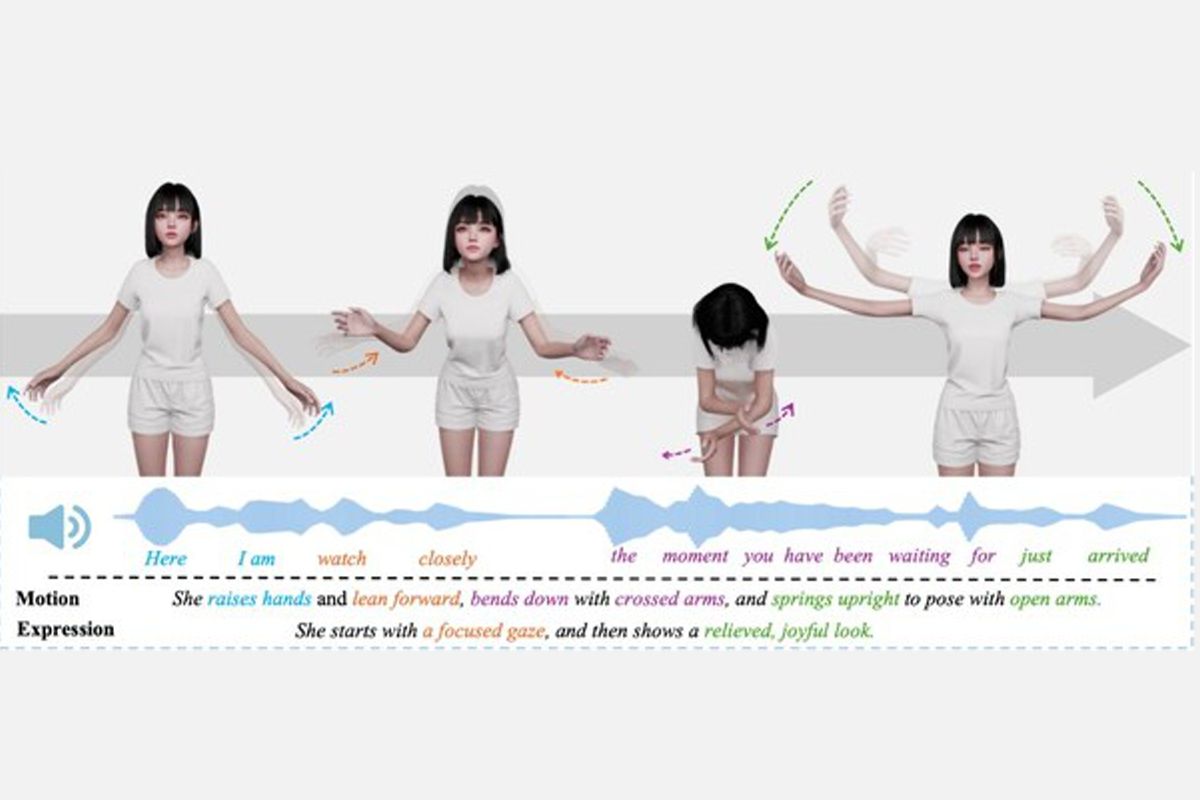
SentiPulse, with researchers from the Gaoling School of Artificial Intelligence at Renmin University, released SentiAvatar, an open-source framework for building expressive interactive 3D digital humans. The package on GitHub includes the SUSU character model, the SuSuInterActs multimodal motion dataset and a pre-trained Motion Foundation Model, plus a streaming architecture that aligns speech, gesture, and facial expression in real time. The dataset centers on a single character with 21,000 clips totaling 37 hours of annotated conversational motion in Chinese, while the motion model was pre-trained on a much larger corpus (reported as 200K+ sequences or 676 hours across sources). The system produces low-latency motion, cited at around 0.3 seconds to generate a six-second sequence, enabling live conversational avatars that reduce uncanny, out-of-sync expressions.
What happened
SentiPulse, in collaboration with researchers from the Gaoling School of Artificial Intelligence (GSAI) at Renmin University, released SentiAvatar as an open-source framework for interactive 3D digital humans. The release bundles the SUSU character model, the SuSuInterActs multimodal motion dataset, a pre-trained Motion Foundation Model, and a streaming architecture designed to align speech, gesture, and facial expression for live conversation. The dataset contains 21,000 clips and 37 hours of annotated, synchronized recordings; pretraining data for the motion model is reported as 200K+ sequences in one source and 676 hours in another. The project is available on GitHub for developers and researchers to use and extend.
Technical details
The release tackles three core technical gaps in digital human research: scarcity of high-quality conversational motion data, semantic composition of actions, and temporal synchronization between speech and motion. SuSuInterActs is centered on a single persona, SUSU (age 22), annotated for behavioral text, full-body motion, facial expression, and aligned audio. The authors pre-trained a Motion Foundation Model on a much larger motion corpus to bootstrap generative performance beyond the 37-hour annotation set.
- •The distribution includes the full framework, the SUSU character model, the SuSuInterActs dataset, and a streaming inference stack.
- •Real-time performance is emphasized, with a reported latency of about 0.3 seconds to generate a six-second motion sequence for live interaction.
- •Multimodal alignment models map speech prosody and semantic cues to composite gestures and facial micro-expressions to avoid the uncanny valley.
Context and significance
Delivering naturalistic nonverbal behavior remains the primary bottleneck for believable digital humans despite advances in rendering. SentiAvatar's combination of a curated persona dataset, a foundation motion model, and an engineering-ready streaming pipeline is notable because it moves beyond isolated motion synthesis toward coherent conversational agents where gesture, facial expression, and speech are produced jointly. Open-sourcing these assets lowers the entry cost for research labs, game studios, and product teams building virtual assistants, social VR avatars, or customer-facing agents. The emphasis on a single, consistent character with rich annotations is also a pragmatic design choice; it reduces variability during training and yields more stable behavior than multi-character datasets with inconsistent labeling.
Why practitioners should care
Modelers can reuse the Motion Foundation Model weights to fine-tune on domain-specific personas or languages. Animators and engineers can integrate the streaming stack into real-time engines to evaluate latency and perceptual quality. Researchers gain access to a high-quality Chinese conversational motion corpus, addressing a geographic dataset gap that has slowed non-English progress in this area.
What to watch
Adoption will hinge on community validation: reproduced quality metrics, perceptual user studies comparing SentiAvatar-driven agents to existing baselines, and how easily the streaming stack integrates with common engines and runtime constraints. Also watch for forks that expand beyond the SUSU persona into multi-persona or multi-language datasets, and for hybrid pipelines that combine SentiAvatar motion outputs with lip-sync and photorealistic rendering layers.
Bottom line
SentiAvatar is a pragmatic, open-source step toward escaping the uncanny valley by aligning multimodal signals in real time. For teams focused on conversational agents and realistic avatars, this release provides ready-to-use data, model weights, and an inference pipeline, enabling faster iteration and more consistent behavior across live interactive scenarios.
Key Points
- 1SentiPulse open-sourced SentiAvatar, bundling a character model, dataset, motion foundation model, and streaming pipeline for real-time avatars.
- 2A focused dataset, SuSuInterActs, offers 21,000 clips and 37 hours of synchronized conversational motion, addressing Chinese-language data scarcity.
- 3Pretrained motion weights (reported as 200K+ sequences or 676 hours) plus ~0.3s generation latency enable practical live synchronization of speech, gesture, and expression.
Scoring Rationale
Open-sourcing a complete dataset, foundation motion model, and streaming stack materially lowers the barrier for realistic conversational avatars, a notable advance for applied research and product teams. The story is domain-specific rather than field-transforming, and the April 9 release date reduces immediacy, yielding a mid-high impact score.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems