Researchers Demonstrate Scalable On-Hardware Quantum Neural Network Training
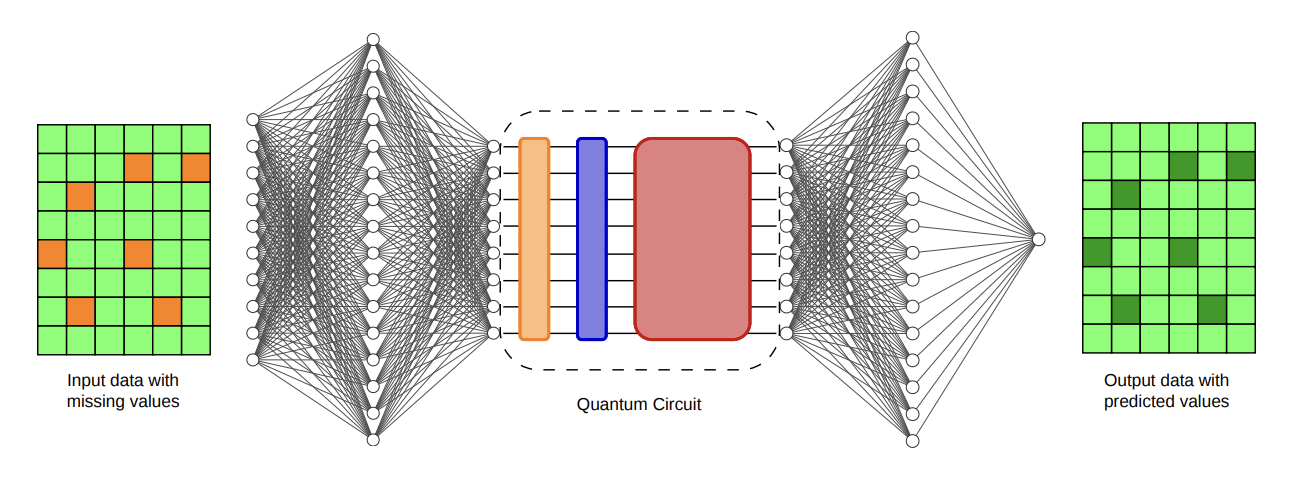
According to an arXiv paper (arXiv:2606.03517, submitted June 2, 2026), researchers introduce a training framework that cuts the gradient-estimation cost of quantum neural networks from scaling quadratically in the number of parameters to scaling logarithmically in the number of qubits. The framework combines a structured Butterfly circuit architecture, a layer-wise training strategy, and a parallelized parameter-shift rule, validated on clinical data imputation with the MIMIC-III dataset. The authors report training hybrid classical-quantum models directly on IonQ's Forte Enterprise trapped-ion hardware at 16 qubits, using tensor-network simulation at 32-qubit scale for training and running 32-qubit inference on hardware, with results matching or exceeding strong classical baselines on patient-survival prediction. The work is a notable step for quantum machine learning experiments that optimize directly on hardware rather than only in simulation.
What happened
According to the arXiv paper (arXiv:2606.03517, submitted June 2, 2026; authors include Natansh Mathur, Panagiotis Barkoutsos, Masako Yamada, Iordanis Kerenidis, and Martin Roetteler), the authors present a training framework that reduces the cost of gradient estimation for quantum neural networks (QNNs). The paper reports that standard parameter-shift methods require a number of circuit evaluations that grows roughly quadratically with the number of trainable parameters, and that their approach reduces that cost to a quantity that scales logarithmically in the number of qubits. The authors validate the approach on clinical data imputation using the MIMIC-III electronic health record dataset and compare against strong classical neural baselines.
Technical details
According to the paper, the framework combines three co-designed ingredients: a structured, subspace-preserving Butterfly circuit architecture with O(n log n) parameters and logarithmic depth; a layer-wise training strategy that confines on-hardware optimization to one small, well-structured layer at a time; and a parallelized parameter-shift rule that exploits commuting structure within each Butterfly layer to extract gradients with a constant number of circuit executions per layer. The paper states that together these reduce the number of distinct circuit evaluations per optimization step from O(n^2) to O(log n).
On-hardware demonstration
According to the arXiv submission, the authors trained hybrid classical-quantum models directly on IonQ's Forte Enterprise trapped-ion hardware at 16 qubits without performance degradation relative to ideal or noisy simulation. They used tensor-network simulation at 32-qubit scale during training and executed 32-qubit inference directly on hardware. The paper reports that the resulting models match or exceed strong classical neural baselines for downstream patient survival prediction while showing reduced variance across runs.
Industry context
Quantum machine learning experiments have long been constrained by gradient-estimation overhead, which typically forces researchers to rely on simulation or tiny hardware experiments. The combination of a structured ansatz (the Butterfly circuit), layer-wise optimization, and parallel parameter-shift exploitation is an example of algorithm-hardware co-design intended to lower experimental cost and noise exposure during training. Comparable efforts in the literature aim to trade circuit expressivity for trainability and measurement efficiency to make on-device optimization feasible.
Implications for practitioners and researchers
The reported reduction from polynomial to logarithmic distinct circuit evaluations per step could materially change the feasibility envelope for on-hardware QNN experiments, particularly on systems with long coherence times and high gate fidelities such as trapped-ion devices. When measurement or gradient costs drop, researchers typically scale experiments to larger ansatzes and place more emphasis on hyperparameter stability and error-mitigation techniques.
What to watch
- •Reproducibility: independent reproductions on other hardware platforms, and open-source code implementing the Butterfly layers and parallel parameter-shift technique.
- •Scalability: demonstrations that extend on-hardware training beyond 16 qubits, with wall-clock training time and shot budgets versus prior methods.
- •Benchmarking: exact classical baselines, hyperparameter settings, and statistical significance of the reported gains on the MIMIC-III tasks.
The arXiv paper and its InspireHEP index entry provide the technical claims and the on-hardware demonstration; the paper contains the circuit diagrams, complexity statements, and clinical-data experiments that underpin the reported results.
Key Points
- 1Authors present a co-designed framework that reportedly cuts gradient-evaluation scaling from O(n^2) to O(log n), easing on-hardware QNN training.
- 2The paper reports 16-qubit on-hardware training and 32-qubit inference on IonQ's Forte Enterprise, matching or beating strong classical baselines.
- 3Lower measurement and gradient costs typically let researchers scale QNN experiments and refocus on error mitigation and reproducibility.
Scoring Rationale
A credible quantum-ML team reports an algorithm-hardware co-design that lowers gradient-estimation cost and demonstrates on-hardware training at 16 qubits with 32-qubit inference on IonQ hardware, a real advance for QNN training. As a niche, not-yet-peer-reviewed preprint, its immediate relevance is mainly to quantum-ML researchers, placing it in the solid range.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems


