Merlin Integrates AI IDs into eBird Database
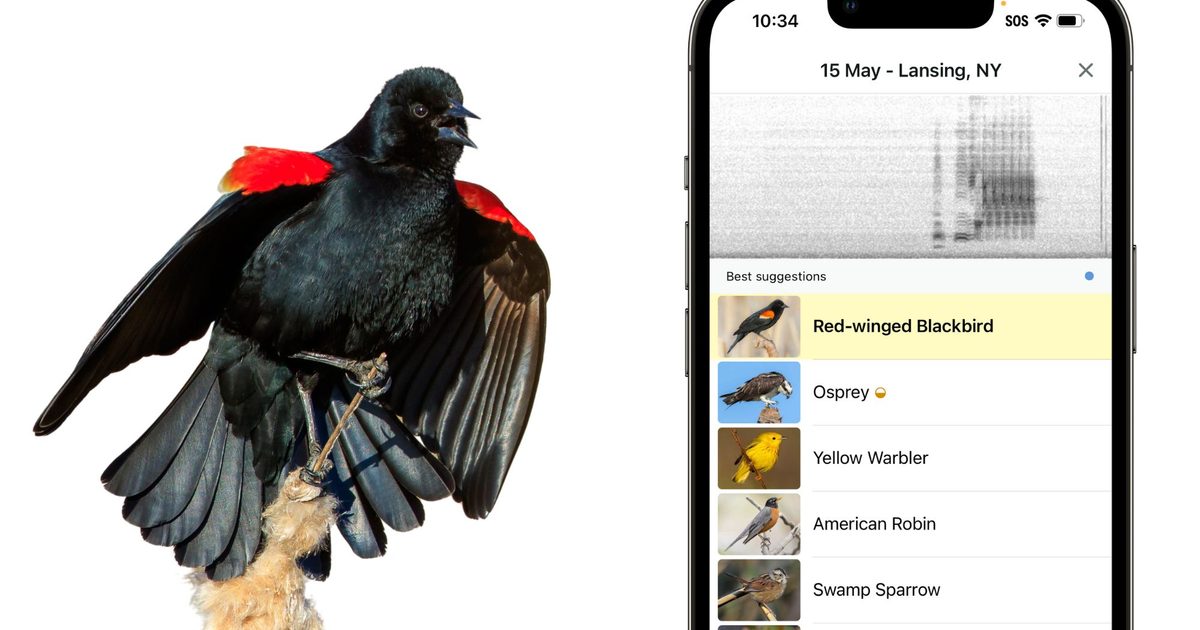
Cornell Lab's Merlin Bird ID will feed AI-assisted bird detections into eBird, a citizen-science platform with more than 2 billion bird observations, according to a July 4 Guardian report. The report says Merlin's Sound ID feature has used machine learning since 2021 and can identify about 2,066 bird species across several regions. For data-science teams, the important change is provenance: a larger stream of real-world audio labels can help bioacoustic models and ecological monitoring, but it also increases the need for confidence scores, metadata, and review workflows. The story is useful as an applied-ML data pipeline shift, not as a frontier-model breakthrough.
The data-science value in this story is not the consumer birding feature by itself. It is the provenance problem created when AI-assisted observations from a mass-market app begin flowing into a scientific database that researchers use for monitoring and modeling.
What happened
The Guardian reported on July 4, 2026, that Cornell Lab of Ornithology plans a closer data link between Merlin Bird ID and eBird. The report says Merlin detections and recordings will be able to feed more directly into eBird, which has more than 2 billion bird observation records. Digital Trends covered the same update from the consumer-tech angle and pointed readers back to The Guardian's reporting.
Technical context
Merlin's Sound ID uses machine learning to suggest birds from audio, while the official Merlin site says users should compare recordings to confirm what they heard. The Guardian reported that Merlin can currently identify about 2,066 species and has more than 40 million downloads across 240 countries. That scale can improve coverage for bioacoustic and biodiversity work, but scale also amplifies label noise when observations are wrong, duplicated, or missing context.
For practitioners
Teams using eBird-derived data should separate human-confirmed observations from AI-assisted detections where the metadata allows it. Useful fields would include model confidence, whether raw audio was attached, location precision, device context, and any human review state. Without those fields, a larger corpus can still be valuable, but training and population-estimation pipelines need stricter cleaning and uncertainty handling.
What to watch
The practical test is whether Cornell exposes provenance and verification controls as the integration rolls out. The Guardian quoted both enthusiasm for broader conservation data and caution about Merlin misidentifications, so downstream users should treat the new flow as a higher-volume signal that still needs validation rather than as automatically ground-truth ecological evidence.
Key Points
- 1Merlin's eBird link could expand real-world labeled audio, but AI-origin records need explicit provenance and confidence metadata.
- 2Guardian reporting cites 2 billion eBird observations and 2,066 Merlin species, making scale and label quality central.
- 3Researchers using the data should separate consumer identification from verified ecological evidence before training models or estimating populations.
Scoring Rationale
This is a solid applied-ML and data-governance story because it changes how AI-assisted field observations may enter a scientific dataset used by researchers. The impact is meaningful for bioacoustic data pipelines and conservation analytics, but it is not a frontier model release or broad platform shift.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
