Google Cloud Demonstrates Multi-Cluster TPU Inference Setup
The Google Cloud blog post by Ammett Williams (June 2, 2026) documents an experiment that deploys an LLM across two GKE clusters in different regions using TPU v6e accelerators and GKE managed DRANET for networking. Per the post, the test uses the Gemma 3 model stored in Cloud Storage, with each cluster attached to four TPU v6e chips and traffic served via GKE Inference Gateway (the gke-l7-cross-regional-internal-managed-mc type) to enable regional routing and failover. Google Cloud documentation and a linked codelab provide step-by-step configuration for VPC, reservations, ComputeClasses/ResourceClaimTemplates, and Gateway/HTTPRoute setups. Additional Google docs on Ray Serve explain model-aware routing and multi-region deployment patterns for centralized traffic management across Ray clusters.
What happened
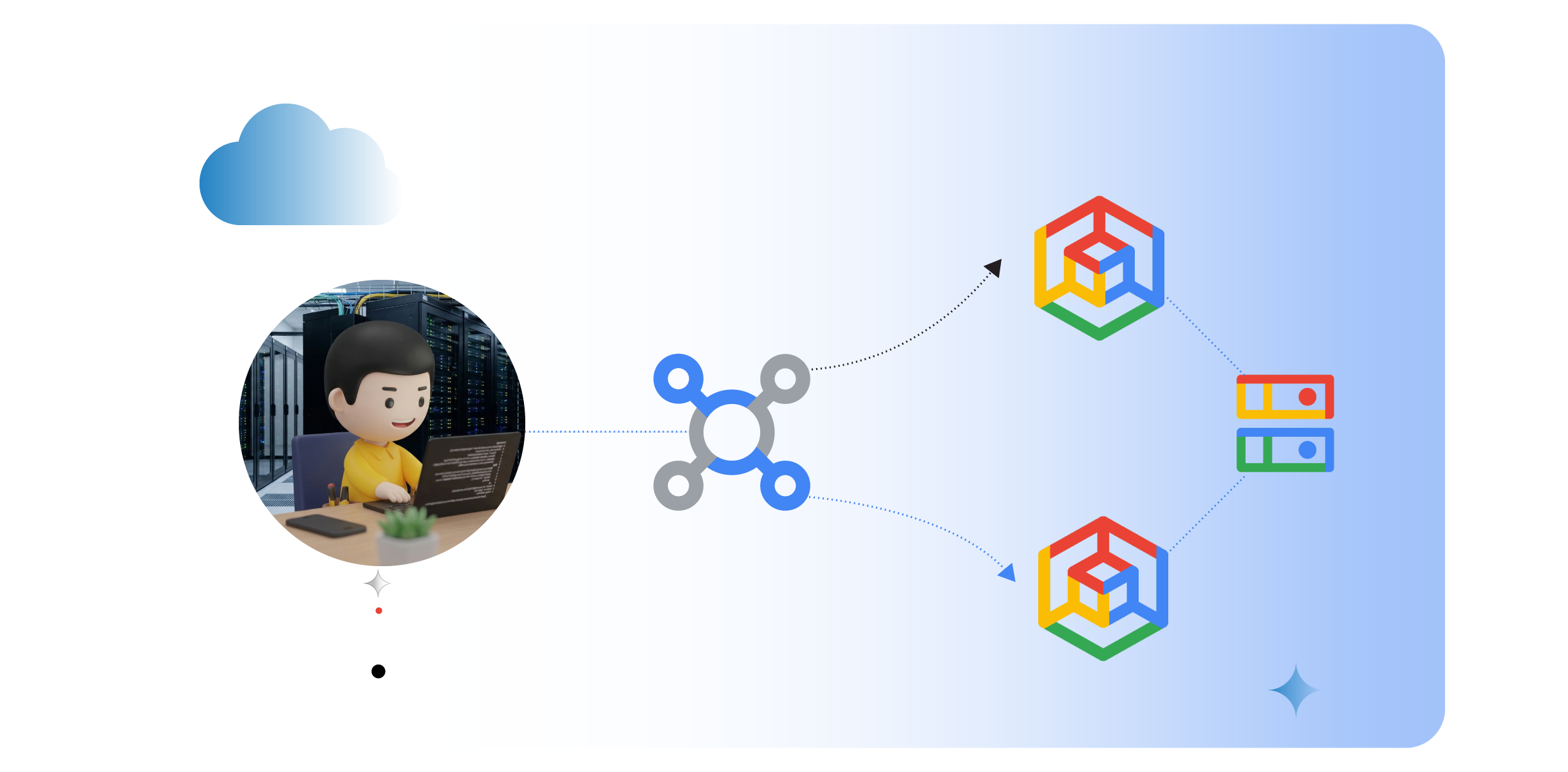
The Google Cloud blog post by Ammett Williams published June 2, 2026, demonstrates an end-to-end experiment that deploys an LLM across two regional Google Kubernetes Engine (GKE) clusters using TPU v6e accelerators and network allocation via GKE managed DRANET. The post describes running Gemma 3 from Cloud Storage, with each cluster using four TPU v6e chips, and exposing inference through GKE Inference Gateway using the gke-l7-cross-regional-internal-managed-mc load-balancer type to enable cross-region routing and failover (Google Cloud blog).
Technical details
The blog and accompanying codelab walk through the required resources: a global VPC, subnet and firewall configuration, TPU reservations in two regions, cluster fleets, and placement of the model artifact in Cloud Storage. The Google Cloud documentation linked in the post explains how to allocate network interfaces for Pods using managed DRANET and how to configure ComputeClass and ResourceClaimTemplate objects to request specialized compute resources (codelab; Google Cloud docs).
Editorial analysis - technical context
Multi-cluster Inference Gateway plus body-aware routing is an emerging pattern for multi-region inference. The Google docs for Ray Serve show model-aware routing via body-based routing extensions, which lets a single external Gateway route to different RayServices or clusters based on the requested model name (Google documentation). Industry implementations often combine centralized Gateway routing with in-cluster inference frameworks to reduce per-cluster endpoint sprawl and to implement model-aware, path-based, or quota-enforced routing.
Context and significance
For teams running production inference at scale, the components shown, managed DRANET for pod-level networking, TPU accelerators for large-model throughput, and a multi-cluster Inference Gateway for traffic control, compose a high-availability architecture that separates traffic management from per-cluster runtime. Reporting and the codelab highlight tradeoffs practitioners already face: reserving scarce accelerators in multiple regions, managing global VPC connectivity, and coordinating configuration across fleet clusters (Google Cloud blog; codelab).
For practitioners
The published codelab and docs provide concrete artifacts to reproduce the experiment, including example ComputeClass/ResourceClaimTemplate configurations, TPU reservation steps, and Gateway/HTTPRoute manifests (codelab). Observers should note the focus on centralized routing primitives and the use of gke-l7-cross-regional-internal-managed-mc for cross-region internal load balancing, as documented in the blog.
What to watch
Industry observers will watch how cloud providers and open-source inference stacks converge on standardized routing primitives (Gateway API extensions, body-based routing) and resource claim patterns for accelerators. Implementers should monitor quota and reservation APIs for TPUs and the evolution of DRANET semantics for cross-region Pod networking, since those affect failover behavior and capacity planning.
Key Points
- 1Google Cloud documents a multi-region inference pattern using GKE, managed DRANET, and TPU v6e for higher availability and failover.
- 2Combining a central Inference Gateway with model-aware routing reduces endpoint sprawl and simplifies routing across multiple Ray or GKE clusters.
- 3Practical adoption depends on accelerator reservations, VPC connectivity, and resource-claim configuration, which are covered in the linked codelab and docs.
Scoring Rationale
The post provides practical, reproducible guidance for building multi-region TPU-backed inference, which matters to teams running large-model serving but does not introduce a new model or paradigm. The content is actionable infrastructure guidance rather than a frontier research breakthrough.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems