Draw Things Integrates Apple Neural Engine into Runtime
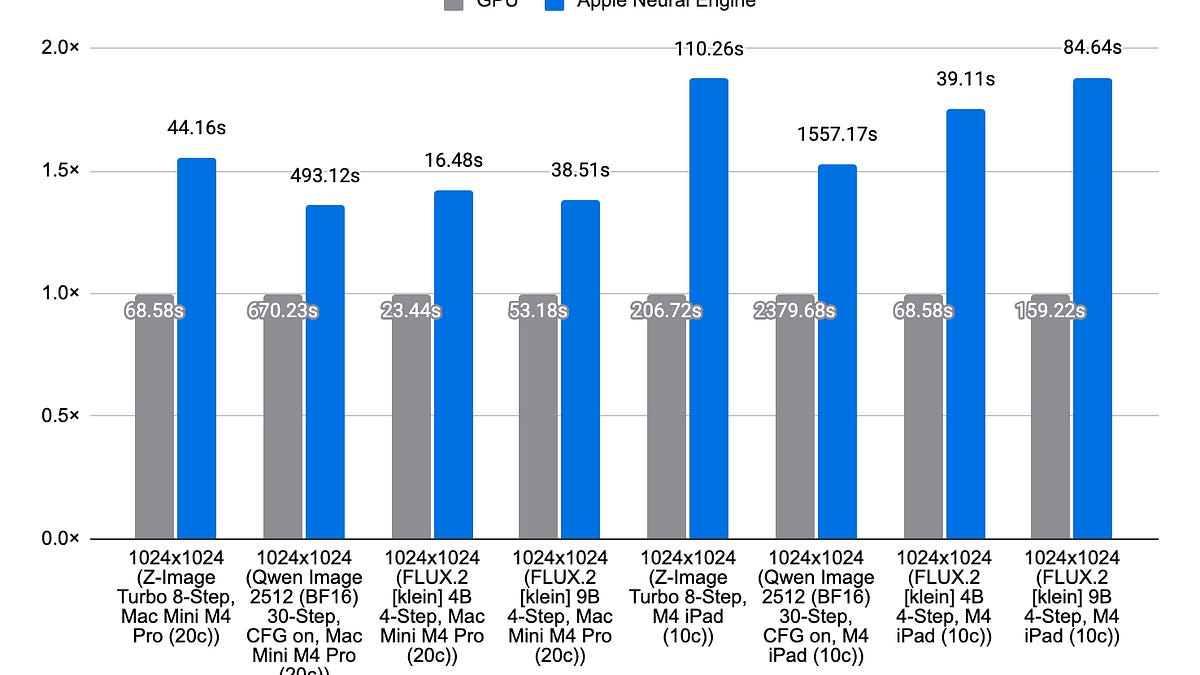
Draw Things has redesigned its inference stack to use the Apple Neural Engine (ANE) as a selective accelerator rather than handing CoreML end-to-end control. In release 1.20260410.1 the team enabled ANE support for 8-bit S models on M3, M4, and M5 Apple silicon, yielding up to 1.8x speed-up on M4 plus lower energy use and cooler operation. The key change is compiling only matrix-multiply kernels into CoreML and invoking them from a custom runtime, preserving memory management, kernel caching, and fine-grained scheduling. macOS 26 and iOS 26 support direct int8 array inputs to CoreML, which removes a major data-movement overhead and makes many small ANE invocations practical. This approach reduces model load times, scratch RAM requirements, and shape rigidity that limited the full-mlpackage strategy.
What happened
Draw Things shipped Apple Neural Engine support in 1.20260410.1, making ANE practical for 8-bit S models on M3, M4, and M5 devices. The new design uses CoreML as an accelerator for selected ops, compiling only matrix multiplication programs into CoreML and invoking them from a custom inference runtime, delivering up to 1.8x speed-up on M4 and lower energy consumption.
Technical details
The earlier path compiled entire PyTorch graphs through coremltools into an mlpackage, producing an mlmodelc that CoreML executed end-to-end. That approach imposed fixed-shape constraints, long first-load times (20-50 seconds), and large scratch RAM needs (3 GiB-4 GiB for a 600M parameter SD 1.5 at 512x512). The new, hybrid approach retains control over intermediate allocations, kernel caching, and scheduling while offloading compute-heavy matrix multiplies to ANE. Two platform changes make this feasible:
- •macOS 26 / iOS 26 now accept int8 arrays directly in CoreML, eliminating costly conversions and copies.
- •Compiling only GEMM-style kernels into CoreML reduces binary size and startup overhead, enabling many fine-grained invocations from the host runtime.
Benefits
- •Faster per-inference throughput, measured up to 1.8x on M4.
- •Lower energy and thermal footprint across M3, M4, M5.
- •Better memory control, avoiding multi-gigabyte scratch allocations.
Context and significance
On-device inference design is converging on hybrid runtimes that mix host-managed memory and scheduling with accelerator kernels. Draw Things demonstrates a practical pattern for leveraging device NPUs without surrendering runtime control, which is crucial for larger, flexible-shape models and interactive workloads. The work sidesteps CoreML's historical shape rigidity and cold-start penalties, and leverages Apple platform OS updates to make int8-based offload performant.
What to watch
Expect this pattern to appear in other runtimes targeting ANE if Apple continues to expand CoreML's low-level data interfaces. Evaluate trade-offs in invocation overhead versus kernel size when porting larger models, and watch for coremltools enhancements that could further reduce friction.
Key Points
- 1Using CoreML as a selective accelerator, not an end-to-end runtime, preserves memory and scheduling control while enabling ANE gains.
- 2Direct int8 array support in macOS 26 and iOS 26 eliminates data-copy overhead, making many fine-grained ANE invocations practical.
- 3Compiling only matrix-multiply kernels reduces load time and scratch RAM, delivering up to 1.8x speed-up on M4 and lower energy use.
Scoring Rationale
This is a notable engineering advance for on-device inference, giving practitioners a repeatable pattern to exploit ANE with real performance and energy benefits. It is not a frontier-model or platform-shifting release, but it materially improves runtime design and should influence other mobile inference stacks.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems

