Tutorialragembeddingsdocument retrievalopen source
Data Teams Build Production-Grade RAG Architecture Locally
8.1
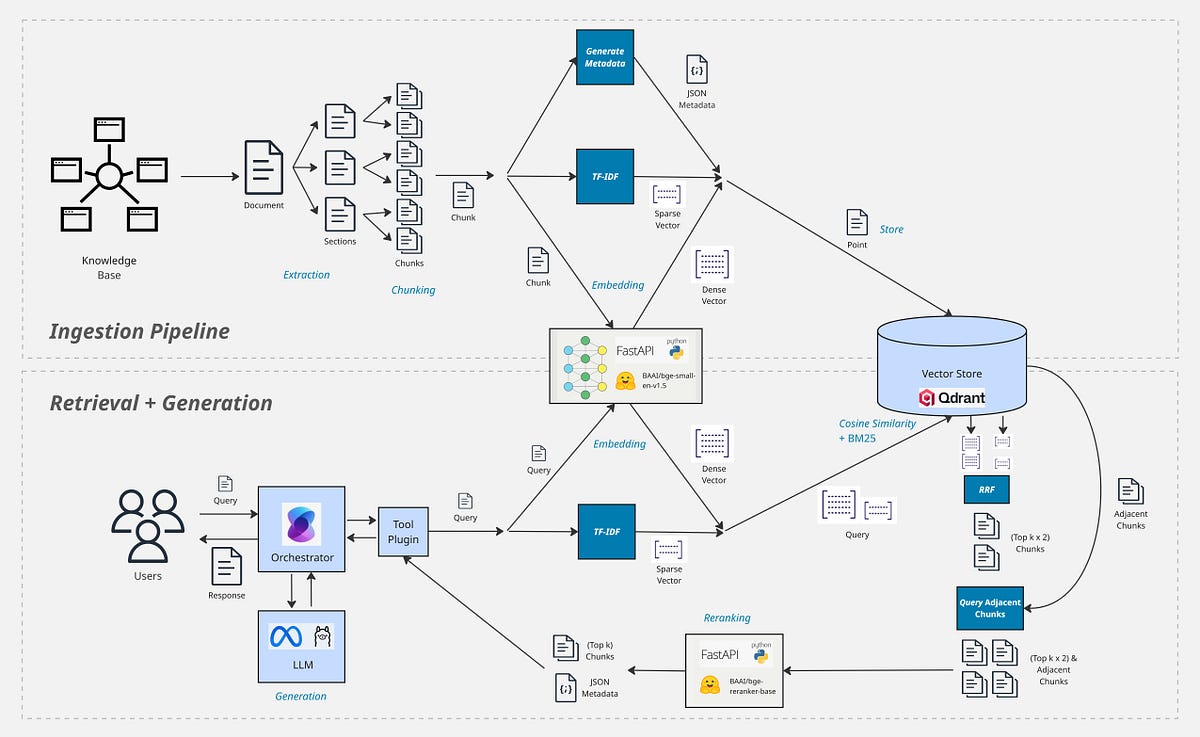
This article presents techniques and best practices for grounding large language models with Retrieval-Augmented Generation (RAG), and builds a complete production‑grade RAG architecture using free, open-source tools. Using PDF versions of the full Kubernetes documentation as the example knowledge base, it walks through key design decisions and provides a runnable GitHub implementation that runs locally for end‑to‑end experimentation.
Key Points
- 1Demonstrate building a RAG pipeline using open-source tools and Kubernetes PDF docs as knowledge base
- 2Reduce hallucinations by grounding LLM outputs in retrieved verifiable documents, increasing overall factual reliability
- 3Offer runnable GitHub solution enabling practitioners to experiment locally and iterate on production designs
Scoring Rationale
High practicality and broad industry relevance drive the score, limited novelty and single-source tutorial constrain impact.
Practice with real FinTech & Trading data
90 SQL & Python problems · 15 industry datasets
Used by DS/ML engineers at top companies
Active Verified Users by Income TierEasyTechnology Stocks with High BetaMediumPortfolio Performance ScorecardHard
250 free problems · No credit card
See all FinTech & Trading problems

