CAISI Evaluates DeepSeek V4 Pro Against Frontier Models
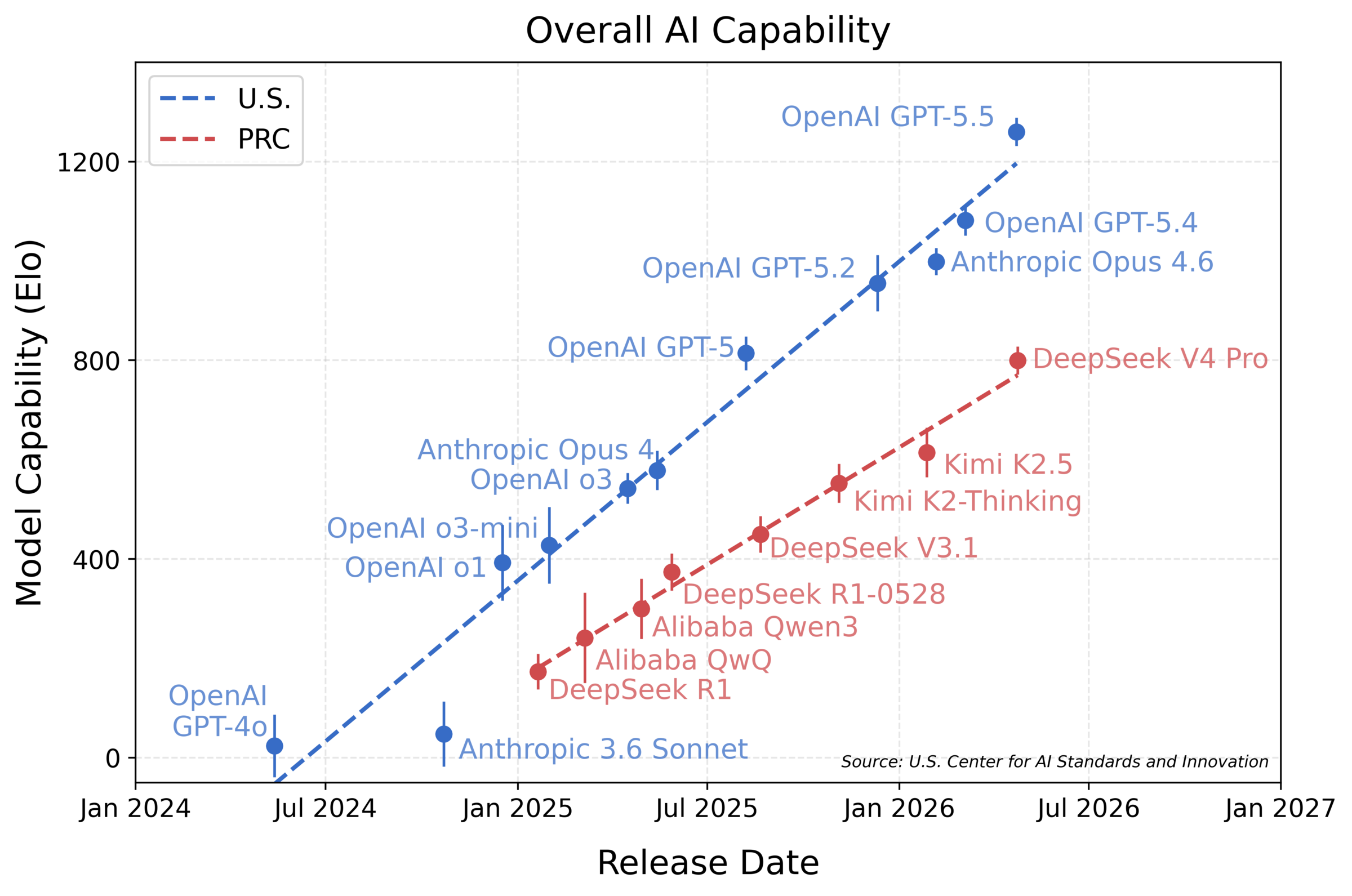
NIST's Center for AI Standards and Innovation published an evaluation of DeepSeek V4 Pro on May 1, 2026. CAISI says DeepSeek V4 is the most capable PRC AI model it has evaluated so far, but its aggregate capability still lags the frontier by about eight months under CAISI's benchmark suite. The evaluation covers cyber, software engineering, natural sciences, abstract reasoning, and mathematics, and it compares DeepSeek's self-reported results with CAISI's independent tests, including non-public benchmarks. For practitioners, the main lesson is that vendor benchmark claims and independent evaluation results can diverge, especially when benchmark selection, contamination controls, prompting, and scoring differ.
What happened
NIST's Center for AI Standards and Innovation published CAISI Evaluation of DeepSeek V4 Pro on May 1, 2026. The evaluation says DeepSeek V4 is the most capable PRC AI model CAISI has evaluated to date. At the same time, CAISI estimates that the model's aggregate capability lags leading frontier models by roughly eight months.
Key findings
CAISI evaluated DeepSeek V4 across domains including cyber, software engineering, natural sciences, abstract reasoning, and mathematics. The report says DeepSeek V4 scores better on DeepSeek's self-reported evaluations than on CAISI's own evaluations. CAISI's benchmark suite includes non-public evaluations, which is important because public benchmarks can be affected by benchmark leakage, overfitting, prompt tuning, or selective reporting.
The evaluation also discusses cost efficiency. CAISI reports that DeepSeek V4 was more cost efficient than a U.S. reference model on most of the evaluated cost comparisons, while still trailing the frontier in aggregate capability. That creates a more realistic tradeoff for teams: the model may not be the strongest available option, but cost efficiency can still make it competitive for specific workloads.
Technical implication
This is a useful example of why model selection should include independent and private evaluations. Public model cards and release claims are useful starting points, but production teams need tests that reflect their own risk profile, data distribution, latency budget, and failure tolerance. A model that performs well on public coding or reasoning benchmarks may behave differently on internal tasks, adversarial prompts, or domain-specific workflows.
Policy and procurement context
Because CAISI is a public-sector evaluation body, its findings can influence government procurement, enterprise risk reviews, and model-governance discussions. The report does not simply rank models; it demonstrates how independent evaluation can challenge vendor-reported capability narratives while still acknowledging cost advantages.
What to watch
Watch whether DeepSeek responds with updated methodology, whether other independent evaluators reproduce the eight-month gap estimate, and whether enterprises treat cost efficiency as enough to justify deployment in lower-risk workloads. Practitioners should also watch how future CAISI reports handle open-weight models, frontier closed models, and domain-specific safety evaluations.
Key Points
- 1CAISI says DeepSeek V4 Pro is the strongest PRC model it has evaluated, but still trails the frontier by roughly eight months.
- 2The report highlights a gap between DeepSeek self-reported results and independent CAISI evaluations.
- 3The practical lesson is to evaluate models on private, workload-specific tests before accepting vendor benchmark claims.
Scoring Rationale
High-quality government evaluation of a major open-weight model. Strong relevance for AI evaluation, model selection, and governance decisions.
Sources
Primary source and supporting public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems

