Researchllmbenchmarksdataset contaminationarxiv
AI Benchmarks Mislead Users With Inflated Scores
8.1
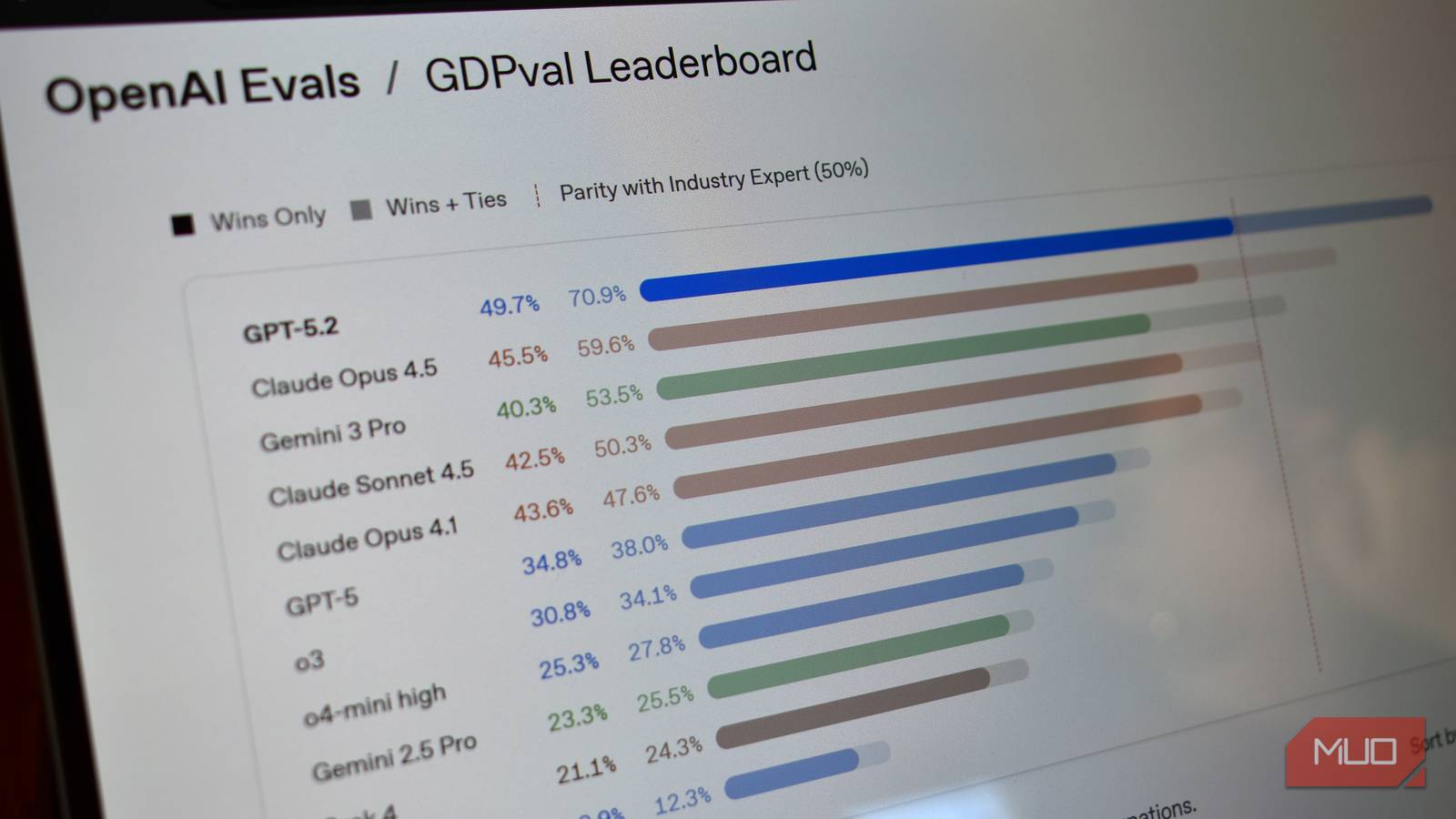
On March 15, 2026, a technology analysis argues that popular AI benchmarks produce misleading signals about model usefulness. The piece details tests like MMLU, GSM8K, and HumanEval and highlights dataset contamination and memorization, citing an arXiv study that found up to a 13% accuracy drop on unseen arithmetic tests. It warns benchmarks often fail to predict real-world performance for summarization, coding, and reasoning tasks.
Key Points
- 1Highlight: Benchmarks like MMLU, GSM8K, and HumanEval measure controlled tasks, not everyday uses.
- 2Explain: Dataset contamination lets models memorize test answers, inflating apparent benchmark performance.
- 3Advise: Practitioners should evaluate models on real-world tasks and clean, unseen benchmark datasets.
Scoring Rationale
High practical relevance and cited ArXiv evidence, limited by reliance on preprints and commentary depth.
Practice with real Logistics & Shipping data
90 SQL & Python problems · 15 industry datasets
Used by DS/ML engineers at top companies
High-Value Overnight OrdersEasyDelivered International ShipmentsMediumOn-Time Delivery Rate by CarrierHard
250 free problems · No credit card
See all Logistics & Shipping problems


