Trellis Introduces RadixAttention KV Prefix Cache
In a Trellis blog post, the company said it is adding RadixAttention - a radix-tree-based KV cache that speeds the prefill phase of LLM inference - to its on-hardware inference stack for laptops, workstations, and servers. RadixAttention was originally introduced by the SGLang project (LMSYS) in 2023-2024; Trellis is implementing the technique, not inventing it. A radix tree stores shared prompt prefixes compactly, collapsing common substrings such as a repeated system prompt into single entries, so sessions that reuse templates avoid recomputing and re-storing the same keys and values. Trellis frames the benefit as lower prefill latency and reduced memory duplication for chat-style and agentic workloads where many requests share a common prefix.
What happened
In a blog post, Trellis said it is integrating RadixAttention, a radix-tree-based KV cache, into its inference stack to speed the prefill phase of LLM serving on users' existing hardware, including laptops, workstations, and servers. Trellis describes the optimization as most useful for chat-style and agentic sessions whose requests share common prompt prefixes.
How it works
Per the Trellis blog post, the system keeps keys and values append-only during generation and stores shared prefixes in a radix tree, which collapses common substrings (for example, a shared system prompt) into single entries. When a new request matches a cached prefix, the corresponding key/value tensors are reused instead of being recomputed and re-stored.
Attribution and context
RadixAttention is not new to Trellis. The technique was introduced by the SGLang project from LMSYS in 2023-2024, described in the SGLang paper and LMSYS's accompanying write-up, where a radix tree manages an LRU cache of key/value tensors for automatic prefix reuse. Trellis's contribution, as described, is implementing and packaging RadixAttention for local and on-premises deployment rather than originating the method.
Editorial analysis - technical context
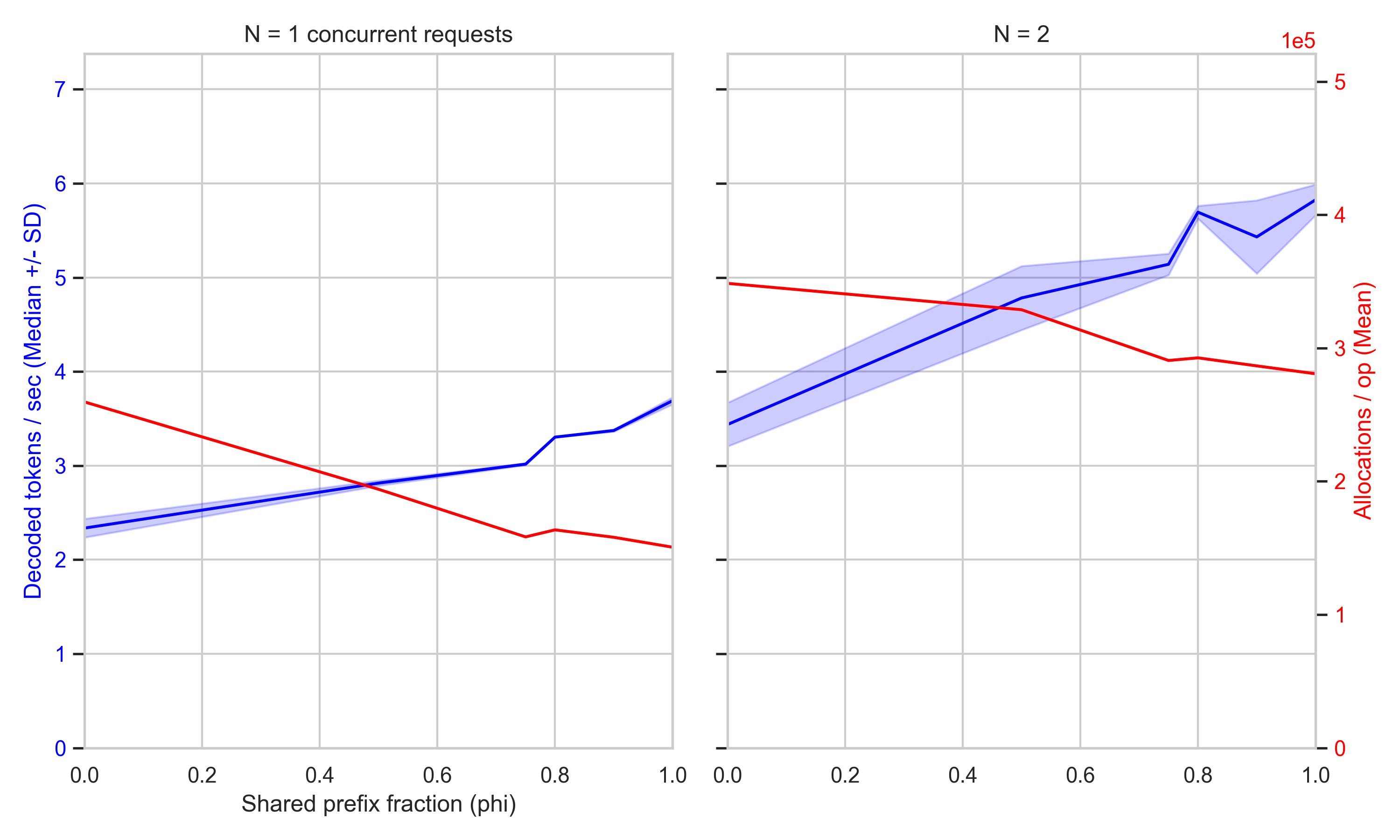
Radix-based prefix caching is a well-established lever for reducing both memory footprint and prefill compute when many sessions reuse templates. The trade-off is the overhead of maintaining an indexed prefix structure and handling lookups, insertion, and eviction; benefits scale with the share of cached prefix tokens.
What to watch
Look for published benchmark numbers from Trellis, comparisons against other prefix-caching implementations such as vLLM and SGLang, and evidence of latency and memory gains on the local-hardware targets Trellis emphasizes.
Key Points
- 1Trellis is bringing RadixAttention - a prefix KV-caching technique originated by the SGLang project - to its own LLM inference stack, rather than introducing a new method.
- 2A radix tree deduplicates shared prompt prefixes, cutting redundant key/value storage and prefill compute when sessions reuse templates.
- 3The optimization mainly benefits chat and agentic workloads on local hardware; real-world gains depend on prefix-sharing rates and published benchmarks.
Scoring Rationale
A vendor blog post describing Trellis adopting an existing inference optimization (RadixAttention, originated by the SGLang project at LMSYS) rather than introducing a new technique. Useful niche tooling for local LLM serving but not a novel contribution, so it is scored in the mid-5s; the prior 6.6 overstated novelty, and the framing was corrected to credit SGLang.
Sources
Public references used for this report.
Practice with real Ad Tech data
90 SQL & Python problems · 15 industry datasets
250 free problems · No credit card
See all Ad Tech problems