Stable Diffusion Explains Latent Diffusion Image Generation
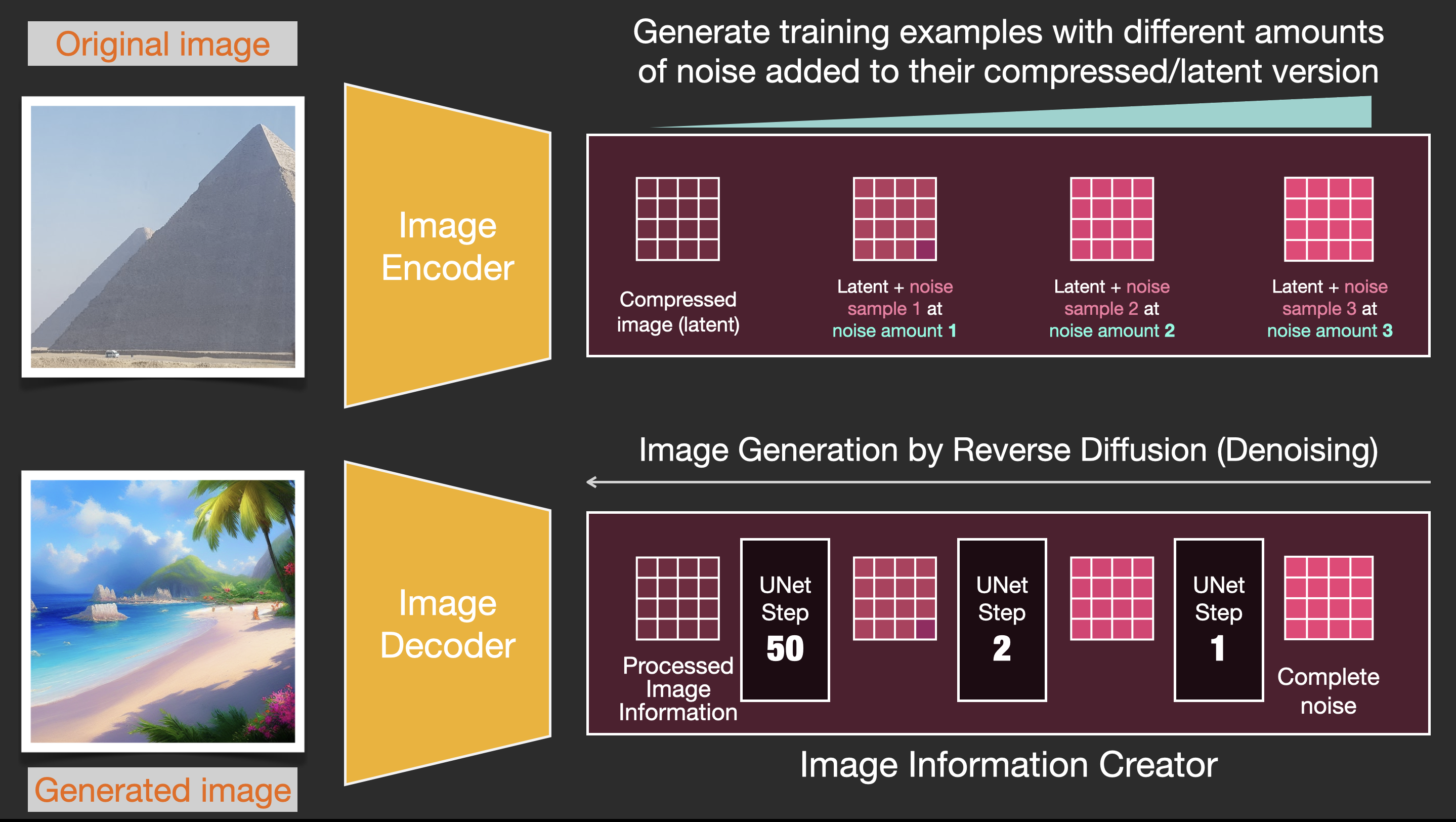
This Nov 2022 updated explainer breaks down how Stable Diffusion generates images from text, describing its CLIP text encoder, UNet-based latent diffusion process, and autoencoder decoder. It notes operational details—77×768 token embeddings, diffusion steps commonly set to 50–100, latent shape (4,64,64) decoded to (3,512,512)—and explains training with noisy-image denoising on datasets such as LAION Aesthetics, highlighting latent-space speed gains.
Key Points
- 1Describes system components: CLIP text encoder, UNet latent denoiser, and autoencoder image decoder.
- 2Explains latent-space diffusion yields faster, higher-quality generation than pixel-space diffusion.
- 3Implies practitioners can tune steps, guidance, and latents for quality, speed, and prompt control.
Scoring Rationale
Comprehensive, practical breakdown of Stable Diffusion components and parameters + limited original research or novel claims.
Sources
Primary source and supporting public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems