SQL Server 2025 Adds Built-in Chunking and Vector Support
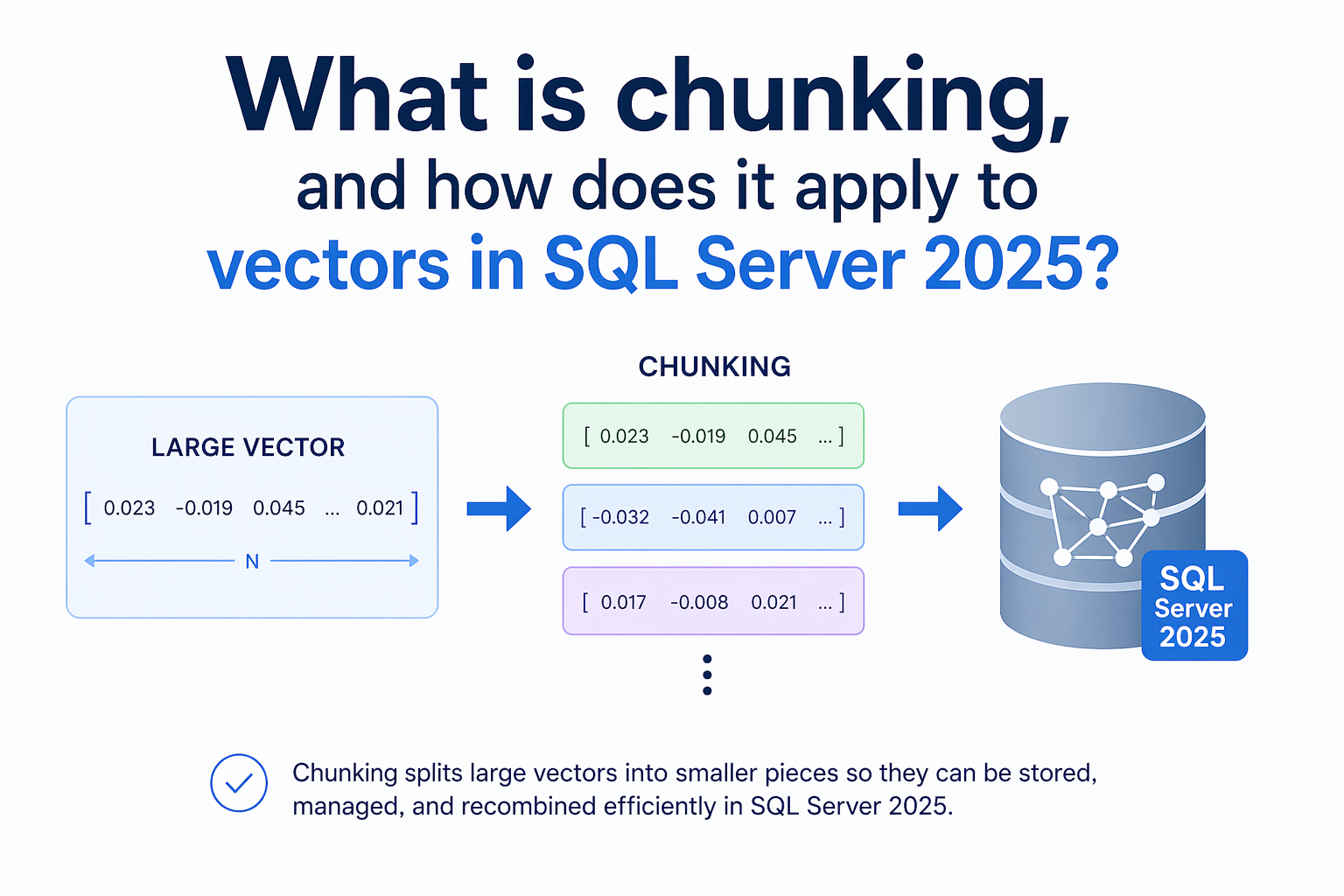
Greg Low explains chunking as the practice of splitting large documents into smaller text fragments before generating embeddings, and he argues chunk size directly affects retrieval precision and context (Red Gate Simple Talk). Microsoft announced SQL Server 2025 public preview and describes built-in vector search, T-SQL model definitions, and integrated embedding and chunking functions in the engine (Microsoft SQL blog, May 19, 2025). Microsoft Learn documents the AI_GENERATE_CHUNKS and AI_GENERATE_EMBEDDINGS functions, including parameters such as CHUNK_SIZE and OVERLAP for AI_GENERATE_CHUNKS (Microsoft Learn). For practitioners, having chunking and embedding generation inside the database reduces data-movement and operational friction, but chunking choices remain the key determinant of RAG quality.
What happened
Greg Low published an explainer on chunking and why chunk size affects embedding quality and retrieval accuracy, describing chunking as breaking larger documents into smaller semantic units before generating embeddings (Red Gate Simple Talk). Microsoft announced SQL Server 2025 public preview and highlighted built-in vector search, T-SQL model definitions, and in-engine support for embedding generation and text chunking (Microsoft SQL Server blog, May 19, 2025). Microsoft Learn documents the AI_GENERATE_CHUNKS table-valued function and the AI_GENERATE_EMBEDDINGS function for SQL Server 2025 and specifies parameters including CHUNK_TYPE = FIXED, CHUNK_SIZE, and OVERLAP for AI_GENERATE_CHUNKS and the JSON vector output format for AI_GENERATE_EMBEDDINGS (Microsoft Learn documentation).
Technical details
Editorial analysis - technical context
Embeddings are produced by an external model and returned as numerical vectors; embedding dimensionality depends on the model, and large documents produce averaged vectors that usually lose local specificity, which is why chunking is used to define the unit of meaning (Red Gate Simple Talk). The Microsoft documentation shows AI_GENERATE_CHUNKS exposes explicit controls for fixed-size chunking and overlap, enabling deterministic chunk boundaries and configurable context windows inside T-SQL (Microsoft Learn). The SQL Server product blog also describes model definitions in T-SQL and access to models via REST endpoints, with examples of integrating external runtimes such as OpenAI and Ollama, which lets teams keep model execution isolated from the database engine while invoking embeddings from T-SQL (Microsoft SQL Server blog; Azure/DevBlogs tutorial).
Context and significance
Embeddings plus vector search are central to retrieval-augmented generation (RAG) workflows, and embedding quality depends on how documents are segmented into chunks and which embedding model is used. Putting chunking and embedding generation into the database reduces the number of moving parts in an enterprise pipeline, which can simplify operational deployment and lower data-export risk, according to the product framing in Microsoft's announcement (Microsoft SQL Server blog). Greg Low's explainer emphasizes a practical trade-off: larger chunks increase context but dilute specificity, while smaller chunks increase precision at the expense of lost context (Red Gate Simple Talk).
What to watch
Practical note
Editorial analysis
Observers should track how teams choose chunk sizes and overlap parameters in production, because those choices will shape vector-store density, index performance, and RAG prompt relevance. Also watch integration patterns for external model endpoints named in the Microsoft blog (for example, OpenAI and Ollama) and whether vendors publish reference chunking heuristics or automated chunking options tied to particular embedding models. Finally, measure end-to-end latency and index storage costs when embedding generation happens inside the database versus in a separate pipeline, since each approach has different operational trade-offs (Microsoft SQL Server blog; Microsoft Learn).
For practitioners, the main technical work remains empirical: experiment with chunk sizes and overlap percentages, evaluate retrieval precision on representative queries, and compare embedding models for dimensionality and cost. SQL Server 2025's functions make those experiments reproducible within the database environment, but the quality of RAG outputs will still be driven by chunking strategy and model selection (Red Gate Simple Talk; Microsoft Learn).
Key Points
- 1Built-in chunking and embedding in SQL Server 2025 reduces data movement, letting teams generate and index vectors inside the database.
- 2Chunk configuration (size and overlap) directly trades context for precision; poor chunking degrades RAG relevance.
- 3SQL Server exposes AI_GENERATE_CHUNKS and AI_GENERATE_EMBEDDINGS in T-SQL, enabling model calls via REST endpoints to services like OpenAI or Ollama.
Scoring Rationale
This is a notable product update for enterprise practitioners because it brings vector search and chunking into a widely used on-prem/managed database, lowering integration friction. It is not a frontier-model release, and much of the remaining work is operational (chunking heuristics and model selection), which yields a mid-level impact score.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
