Technical / Researchmodel unlearningdistillationmachine learning robustness
Researchers Apply Distillation Principles to Strengthen Robustness of Machine Unlearning Methods
6.8
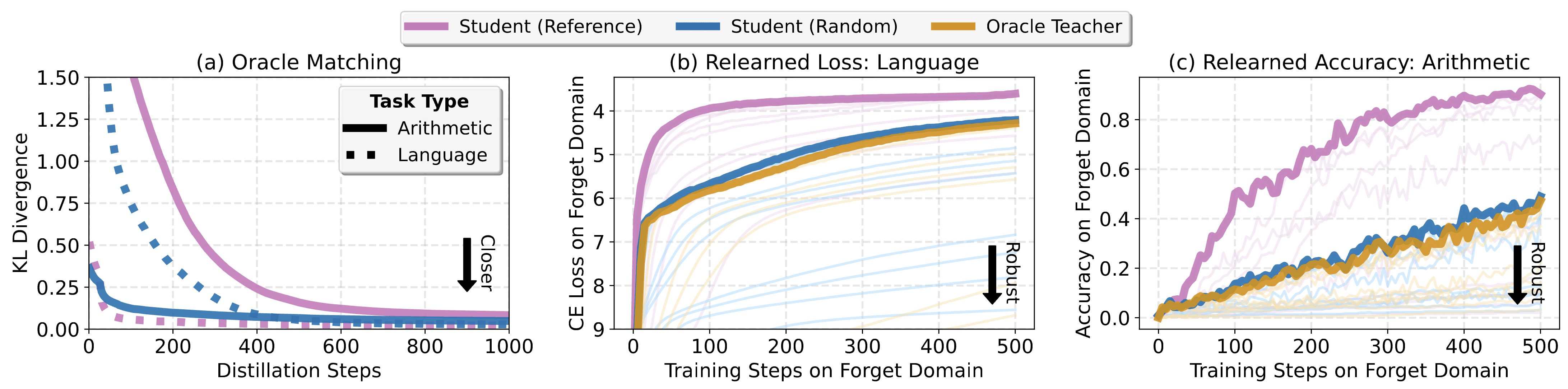
Researchers draw on lessons from model distillation to improve the robustness of machine unlearning. The discussion on LessWrong explores how knowledge distilled into smaller models might preserve essential information while removing specific data traces. This approach could mitigate catastrophic forgetting and privacy risks in unlearning workflows. It frames distillation as both a constraint and enabler for stable model revision.
Key Points
- 1Uses knowledge distillation principles to stabilize machine unlearning processes
- 2Improved robustness could enhance compliance with data deletion requests under AI governance rules
- 3May inform future architectures combining privacy-preserving and continual learning objectives
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
