Opinionnlppost trainingon policy
LessWrong Labels GRPO Post-Training Approach Terrible
3.5
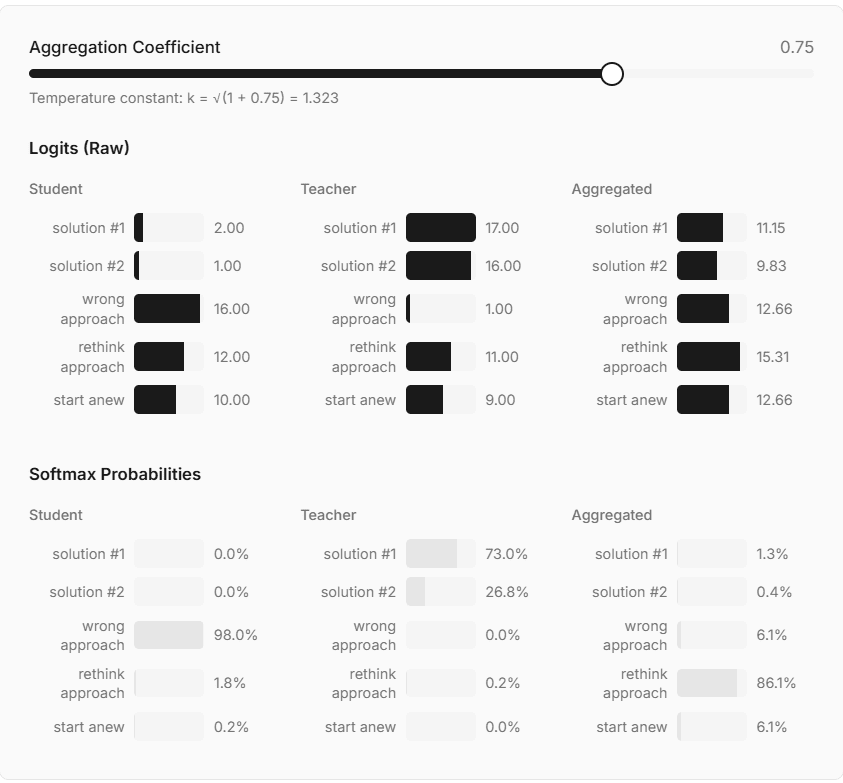
LessWrong criticizes GRPO, calling the on-policy, sample-efficient NLP post-training approach 'terrible.' The RSS description notes the method reportedly does not require verification; full article unavailable, so details and context are limited.
Key Points
- 1Highlights criticism of GRPO as 'terrible' by LessWrong, indicating strong negative assessment.
- 2Likely questions efficacy of an on-policy, sample-efficient post-training NLP method not requiring verification.
- 3May indicate increased scrutiny and debate within ML/NLP communities about GRPO.
Scoring Rationale
Single-source critique flags concerns about a niche NLP post-training method, but RSS-only source limits confidence and detail.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems