Tutorialtransformerstokenizationembeddingssampling
Large Language Models Explain Text Generation Process
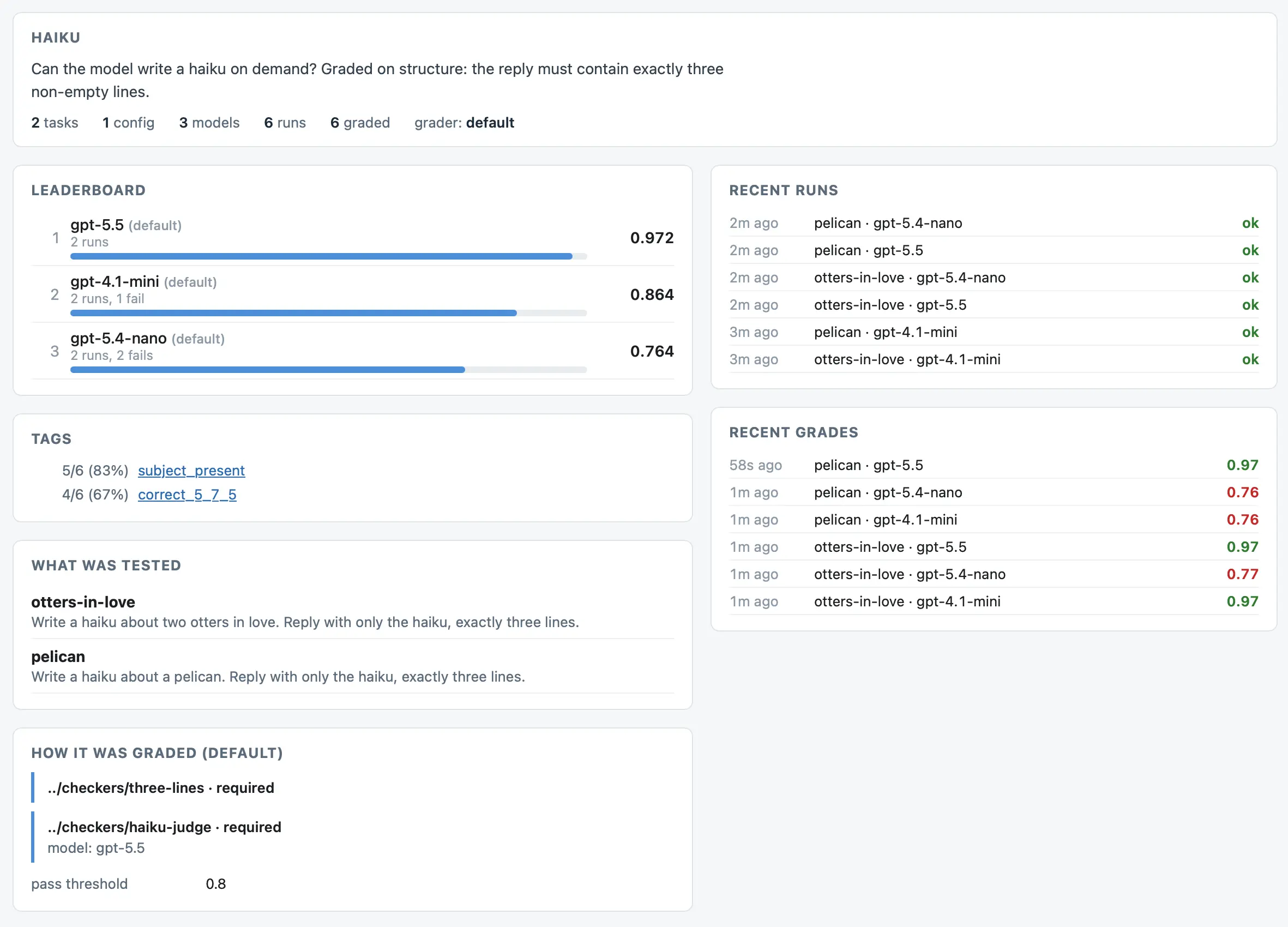
7.8
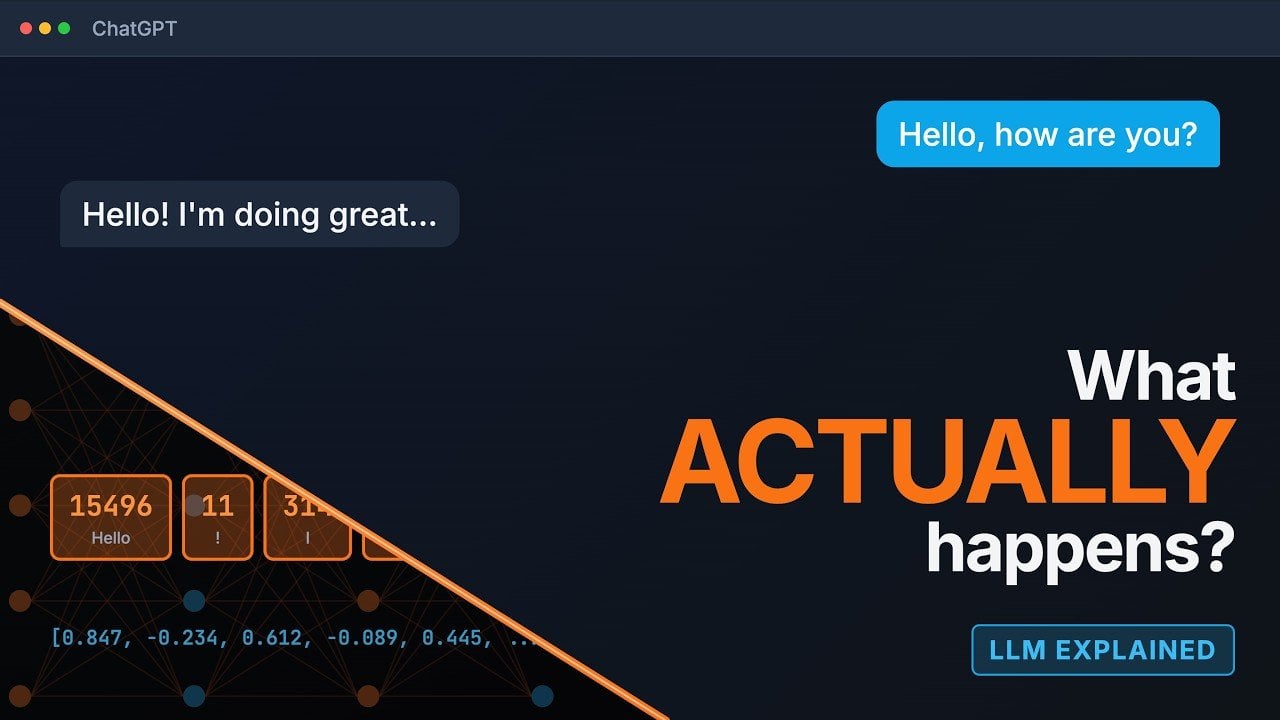
The team at Learn That Stack explains how large language models generate text through five key stages: tokenization, embeddings, transformers, probability scoring, and sampling. The article details each stage's mechanics and practical settings like temperature and top-p, and highlights implications for token limits and hallucination risks. Readers learn actionable advice for optimizing inputs and sampling to balance creativity, cost, and factual reliability.
Key Points
- 1Outline five stages: tokenization, embeddings, transformers, probability scoring, and sampling.
- 2Explain attention-based transformers enable contextual understanding across tokens, improving coherence and relevance.
- 3Advise tuning tokenization and sampling (temperature, top-p) to optimize cost, creativity, and accuracy.
Scoring Rationale
Strong educational overview with practical tips, but largely introductory and lacks novel research or empirical validation.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems