Google DeepMind Launches Veo 3 Video Generator
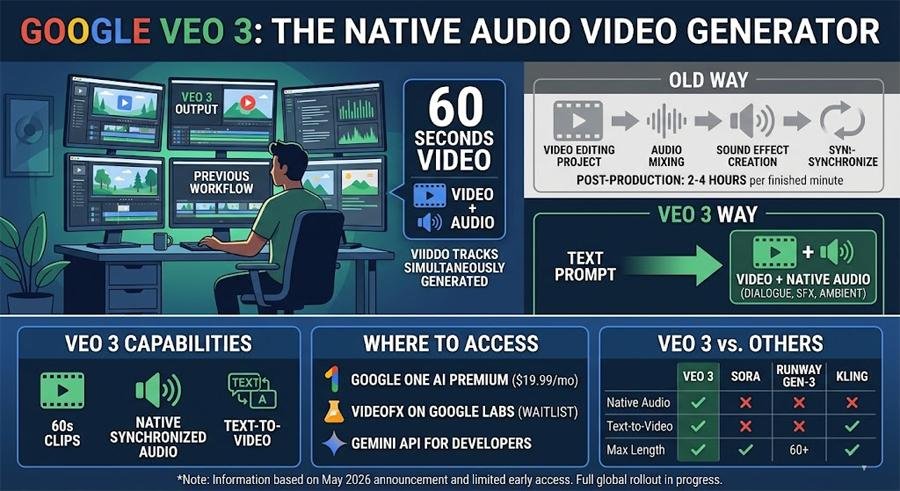
Per a May 16, 2026 review on SmashingApps, Veo 3 is Google DeepMind's new text-to-video model that generates clips up to 60 seconds with native, synchronised audio (dialogue, effects, ambient sound). SmashingApps reports access routes as Google One AI Premium (listed at $19.99/month), Google Labs' VideoFX (waitlist), and the Gemini API for developers. The article frames native audio generation as a substantive workflow change compared with earlier models such as Sora and Runway Gen-3 Alpha, which require separate audio post-production. SmashingApps notes Veo 3 launched in limited access in May 2026 and that the review draws on Google demonstrations, developer API reports, and early user testing. The integration of synchronized audio into a single generative step could materially reduce editing time for short-form content creators and change tooling choices for post-production teams.
Technical details
Editorial analysis - technical context
Contemporary text-to-video systems commonly produce visual frames only or produce audio as a separate artifact that must be edited in later. SmashingApps highlights native audio generation in Veo 3 as a differentiator versus prior tools such as Sora and Runway Gen-3 Alpha, which the article says require separate audio post-production. The review does not publish model architecture, parameter counts, or evaluation metrics; those technical specifics are not present in the SmashingApps report or the DeepMind snippet cited.
Context and significance
Limitations and caveats
What happened
Per a May 16, 2026 article on SmashingApps, Veo 3 is Google DeepMind's latest text-to-video model, announced at Google I/O and described on DeepMind's models page, that generates up to 60 seconds of video from text prompts with native, synchronised audio including dialogue, sound effects, and ambient sound. The SmashingApps piece reports that Veo 3 is available in limited access, and lists access paths as Google One AI Premium (reported price $19.99/month), Google Labs' VideoFX (waitlist), and the Gemini API for developers. The article states the coverage and conclusions are based on Google demonstrations, developer API access reports, and early user testing.
SmashingApps emphasises that Veo 3 rolled out in limited access in May 2026 and that observed capabilities derive from demos, early API reports, and small-scale testing. The article notes broader access is still rolling out and that real-world limitations will become clearer as more creators use the system at scale.
What to watch
Editorial analysis
For practitioners, the key implication is a potential workflow shift. When a single generative pass yields synchronised audio and video, teams that routinely spend hours adding dialogue, ambient tracks, and Foley to generated visuals could re-evaluate toolchains, template libraries, and QA steps for lip sync and audio consistency. This is a generic industry observation based on the pattern of toolchain changes seen when previously separate capabilities consolidate into one API.
Observers and practitioners should track API rate limits, content-moderation constraints, export codecs, and lip-sync accuracy on longer dialogues as early indicators of production readiness. Also watch for published evaluation metrics from DeepMind or independent reviewers to replace demo-based claims with measurable benchmarks.
Key Points
- 1Veo 3 combines text-to-video with native synchronized audio, reducing separate audio post-production work for short clips.
- 2Limited access and demo-based reporting mean practitioners should validate quality and scale on their own workloads.
- 3If audio+video generation is robust, editorial and post pipelines may shift toward single-pass generative workflows for short-form content.
Scoring Rationale
A capability that produces synchronised audio with generated video is a notable product advance with practical workflow impact for content creators and ML engineers, but the announcement is currently limited-access and lacks published benchmarks, which reduces near-term certainty.
Sources
Primary source and supporting public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems

