Google Cloud Integrates LLM Calls into Pub/Sub
Google Cloud now offers an AI Inference transform for Pub/Sub that makes it simple to invoke LLMs at the messaging layer, either at the Topic or Subscription level. The feature lets you call Google, partner, or custom models from a transform applied to messages, using the Console or gcloud CLI to configure behavior. This simplifies tasks like generating personalized text, enriching events, or sanitizing data before delivery, but it also centralizes business logic in the message plane. That creates operational trade-offs around latency, cost, observability, retry semantics, idempotency, and data governance. Practitioners should weigh convenience against these risks and design clear boundaries for where inference runs, how failures are handled, and what models are allowed to access sensitive payloads.
What happened
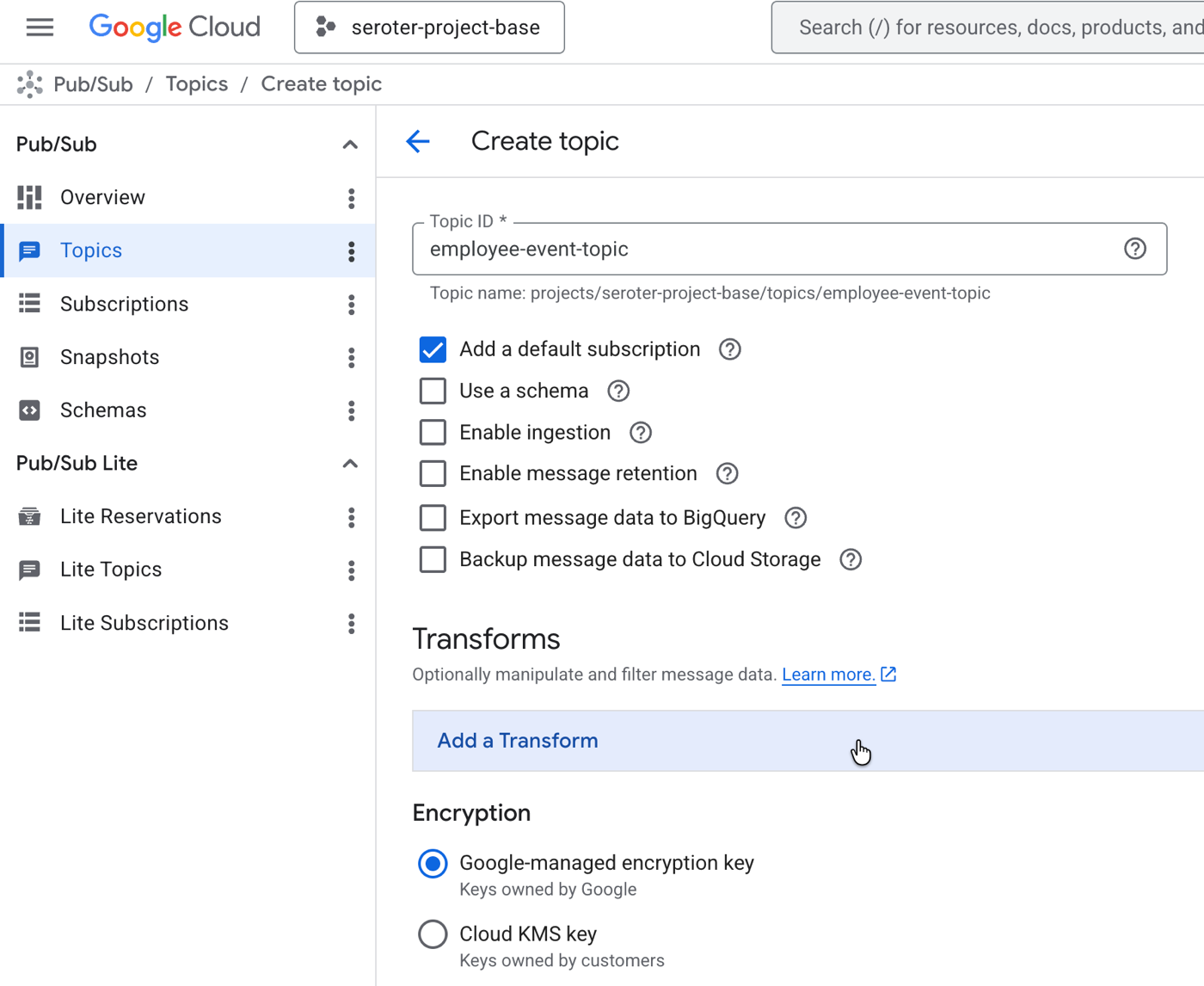
Google Cloud introduced an AI Inference transform for Pub/Sub that enables calling LLMs from a Topic or Subscription transform. The new AI Inference SMT can invoke Google, partner, or custom models and is configurable via the Console or gcloud CLI. This lets teams enrich, sanitize, or generate message payloads upstream of downstream consumers instead of pushing inference into each subscriber.
Technical details
The transform attaches at either the Topic or Subscription level, so you can alter every subscription's delivered message or target specific subscribers. Configuration is done through the Console or gcloud commands and supports selecting model endpoints and invocation parameters. Important technical considerations include synchronous inference latency added to the messaging path, billing for inference invoked per message, and the need for idempotent transforms because Pub/Sub retries can re-run inference. Observability and debugging shift from consumer services into the message layer, and you must ensure trace context and metrics propagate from transform to final consumer.
Operational trade-offs
Use of AI Inference SMT centralizes business logic and can simplify downstream consumers, but it also concentrates operational responsibilities. Key risks to assess are:
- •increased end-to-end latency and variable tail latency when models are invoked inline
- •unpredictable costs from high-frequency inference calls, especially during retries
- •failure modes where transform errors cause message backpressure or altered retry behavior
- •privacy and governance concerns when sensitive fields are sent to external models
Why it matters
This feature changes architectural choices for event-driven systems. Teams can reuse a single enrichment pipeline rather than duplicating model clients across services, reducing integration overhead. However, it also moves decision authority into the messaging tier, which historically should be lightweight and predictable. For ML engineers and platform teams, this creates new responsibilities around SLA targets, model selection policies, access controls, and monitoring.
What to watch
Establish clear rules for which messages run inference, implement strict model allowlists and PII protections, and design transforms to be idempotent and fail-safe. Evaluate cost and latency on representative workloads before migrating production logic into the message plane.
Key Points
- 1Centralizing LLM calls in Pub/Sub simplifies downstream consumers but concentrates latency, cost, and failure modes in the messaging layer.
- 2Applying an AI Inference SMT at Topic or Subscription level allows reuse and consistent enrichment, requiring idempotency and retry-aware design.
- 3Operational controls-model allowlists, PII protections, observability, and cost caps-are essential before shifting business logic into Pub/Sub transforms.
Scoring Rationale
This is a notable product-level change that affects architecture patterns for event-driven systems. It gives practical convenience but introduces operational and governance risks practitioners must manage.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems


