Databricks Announces Storage Optimized Vector Search
AI-assisted, source-derived brief produced by the Let's Data Science Automated News Desk. The source material used is linked on this page.
- Source event:
- first reported
- LDS brief:
- publication time is not available in the public LDS lifecycle record
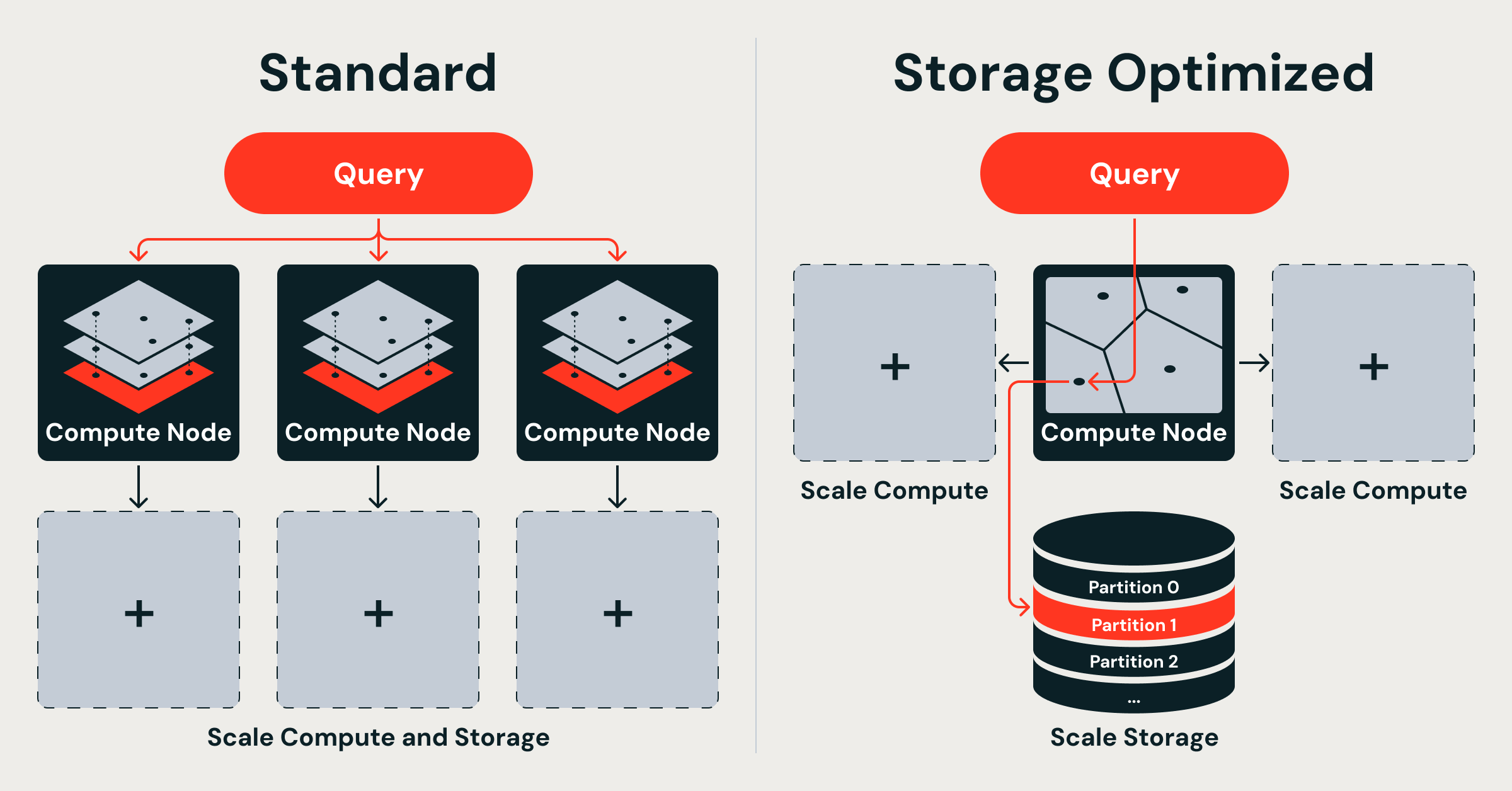
Databricks today unveiled Storage Optimized Vector Search, offering Standard and Storage Optimized endpoints to serve billions of embeddings by separating storage from compute. The system uses object-storage-backed IVF indexes, distributed PySpark ingestion (distributed K-means, product quantization), and a Rust dual-runtime query engine, delivering billion-vector indexes in under eight hours, 20x faster indexing and up to 7x lower serving costs. The design trades lower latency for cost-efficient scale.
Key Points
- 1Separates storage from compute using object storage-backed indexes, enabling billion-vector scale without node replication
- 2Implements distributed IVF indexing and Spark-based ingestion to speed indexing and scale linearly with executors
- 3Delivers operational gains: billion-vector builds under eight hours, 20x faster indexing, and up to 7x lower serving costs
Scoring Rationale
Strong production engineering enabling billion-vector scale and cost reduction, but limited algorithmic novelty beyond established IVF and PQ techniques.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems