codebase-memory-mcp speeds AI coding agent queries
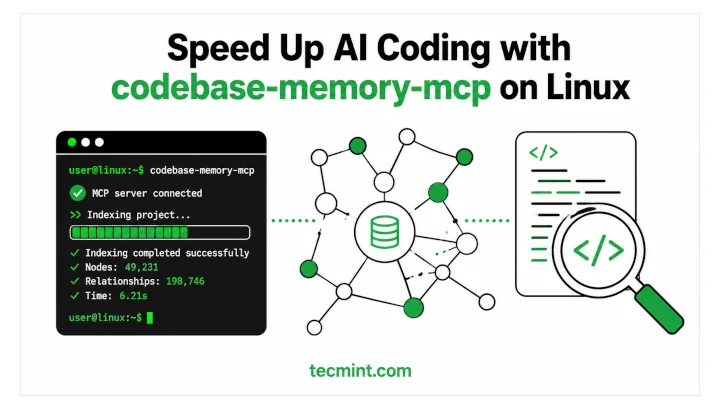
The open-source tool codebase-memory-mcp from developer DeusData indexes an entire codebase across 158 programming languages into a persistent knowledge graph that AI coding agents such as Claude Code and Codex CLI can query directly instead of re-scanning files, according to the project's GitHub README. The single static C binary indexes the Linux kernel (28 million lines of code) in about 3 minutes and answers structural queries in under a millisecond. The project's own benchmark claims a 99.2% token reduction versus file-by-file search, though an independent reproduction by Agentic Context Research confirmed compact query output while noting the comparison used an unoptimized grep baseline on a single, undisclosed repository. A separate arXiv preprint reports 83% answer quality and 10x fewer tokens across 31 real-world repositories.
For engineers running LLM coding agents against real repositories, the practical bottleneck is rarely the model's reasoning, it's re-reading the same files on every question. A persistent, queryable knowledge graph turns repeated file-by-file exploration into structured lookups, which is the kind of infrastructure choice that determines token spend and iteration speed at production scale more than which model an agent runs on.
What happened
The open-source project codebase-memory-mcp, built by DeusData, full-indexes a repository into a persistent knowledge graph and serves it to coding agents over the Model Context Protocol (MCP). Per the project's GitHub README and independent installation guides from TecMint and russ.cloud, the server ships as a single statically-linked C binary with no runtime dependencies, storing the graph in a local SQLite database. It supports 158 programming languages via vendored tree-sitter grammars, with added semantic resolution for Python, TypeScript/JavaScript, PHP, C#, Go, C, C++, Java, Kotlin, and Rust. The README reports indexing the Linux kernel (28 million lines of code, 75,000 files) in about 3 minutes on an Apple M3 Pro, and answering structural queries in under 1 millisecond.
Technical context
The tool exposes 14 MCP tools covering structural search, call-path tracing, dead-code detection, diff impact analysis, architecture decision record management, and Cypher-style graph queries, and auto-configures 11 coding agents including Claude Code, Codex CLI, and Gemini CLI. Release binaries are signed, checksummed, and scanned by 70-plus antivirus engines, and all indexing runs locally with no telemetry, per the README's security notes. The project also ships an optional 3D graph-visualization UI.
For practitioners
The headline efficiency claim, a 99.2% token reduction (about 3,400 tokens versus 412,000 for five structural queries against file-by-file grep), is the vendor's own single-scenario benchmark on an undisclosed repository. Agentic Context Research, an independent group that reproduces coding-agent benchmarks, replicated the live queries and confirmed the compact output, but flagged that the comparison baseline is naive grep rather than optimized or RAG-based file search, and that no reproducible benchmark harness exists, only an author-run session. Teams evaluating this for cost-sensitive agent workflows should treat the 99% figure as directionally credible but re-measure it against their own repositories and retrieval baselines before budgeting savings. A separate arXiv preprint (2603.27277) evaluating the underlying architecture across 31 real-world repositories reports more modest but independently interesting figures: 83% answer quality, 10x fewer tokens, and 2.1x fewer tool calls versus file-by-file exploration.
What to watch
Indexing time and memory footprint on your own CI or workstation hardware, whether structural context reduces hallucination or broken edits in agent-driven code changes, and whether the 22,000-plus-star GitHub project (1,095 commits, 31 releases in nine weeks) sustains its release cadence and security posture as adoption grows.
Key Points
- 1codebase-memory-mcp indexes codebases into a persistent SQLite-backed knowledge graph so AI coding agents can query structure instead of rereading files.
- 2The single static binary answers structural queries in under a millisecond, replacing costly repeated file-by-file exploration during agent sessions.
- 3Independent benchmark reproduction confirms compact query output but flags the vendor's 99% token-savings figure as a favorable single-repo comparison.
Scoring Rationale
A well-documented open-source developer tool with strong primary sourcing (official README, arXiv preprint) and a rare independent benchmark reproduction that both confirms and contextualizes the vendor's efficiency claims. Notable for AI-coding-agent practitioners but a niche infrastructure tool, not an industry-shaking development.
Sources
Primary source and supporting public references used for this report.
View 6 more sources
- DeusData/codebase-memory-mcpgithub.com
- codebase-memory-mcp — Benchmark Reproduction | Agentic Context Researchpantheon-org.github.io
- codebase-memory-mcp: Giving Claude Code (and Codex) a Mapruss.cloud
- Codebase Memory MCP: Give Your AI Coding Agent a ... - CoddyKitcoddykit.com
- codebase-memory-mcp - MCP Servers on GitHub (23.1k stars) | SkillsLLMskillsllm.com
- Codebase Memory Mcp MCP Server — Install & Config | Vibehackersvibehackers.io
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems
