Baidu Releases ERNIE 5.1 with Lower Training Cost
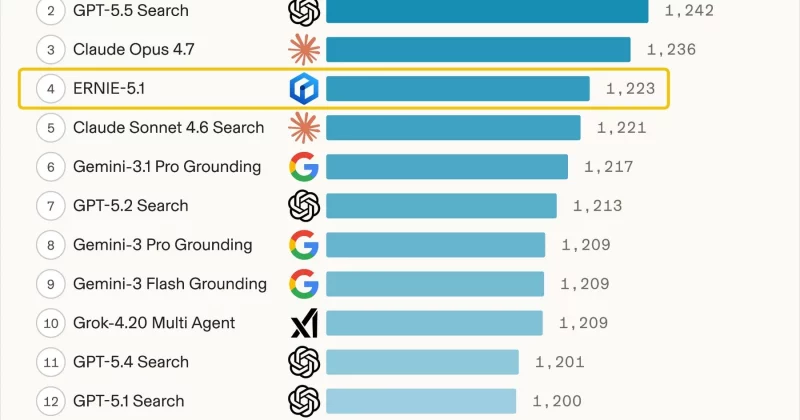
Per Baidu's official blog (May 9, 2026), ERNIE 5.1 is publicly released and, according to the announcement, compresses total parameters to roughly one-third and active parameters to about one-half while claiming comparable pretraining performance at about 6% of the pretraining cost of comparable models. Baidu's post states ERNIE 5.1 scored 1,223 to place 4th globally and 1st among Chinese models on the Arena Search leaderboard. Independent coverage by Decrypt frames the same cost claim as a 94% reduction relative to peers. Reporting and technical analysis outlets such as I-Scoop describe ERNIE 5.1 as derived from ERNIE 5.0 using a Once-For-All elastic training approach and a disaggregated fully-asynchronous reinforcement learning pipeline, per Baidu's documentation.
What happened
Per Baidu's official blog post dated May 9, 2026, Baidu released ERNIE 5.1 as a successor built on the pretraining foundation of ERNIE 5.0, claiming total-parameter compression to approximately one-third and active-parameter reduction to about one-half. Baidu's announcement states the model achieves flagship-level performance using about 6% of the pretraining cost of comparable models and reports a score of 1,223, ranking ERNIE 5.1 4th globally and 1st among Chinese models on the Arena Search leaderboard (Per Baidu's blog). Decrypt summarizes the cost claim as a 94% reduction relative to rival training costs. I-Scoop's coverage and Baidu's blog describe the model as selected from an elastic Once-For-All-style training family derived from ERNIE 5.0 (I-Scoop; Baidu blog).
Technical details
Per Baidu's technical writeup, ERNIE 5.1 was produced by extracting an optimized subnetwork from a larger elastic pretraining run rather than by training an independent model from scratch. Baidu reports a new disaggregated fully-asynchronous reinforcement learning infrastructure intended to address training-inference divergence, resource utilization, and long-tail effects. The blog also attributes additional capability gains to a scaled agentic post-training stage and an end-to-end synergy strategy across environment, expert, and integration phases (Baidu blog).
Editorial analysis - technical context
Industry-pattern observations: Reusing a larger pretrained family and selecting performant subnetworks is consistent with recently explored efficiency strategies such as Once-For-All networks, mixture-of-experts pruning, and sparse activation. These approaches aim to trade raw parameter count for effective active capacity, which can reduce compute during pretraining and inference while preserving task performance. If the method generalizes beyond benchmark tasks, practitioners could expect lower-cost paths to deployable foundation models for many production workloads.
Context and significance
What to watch
Editorial analysis
The headline claim, achieving leaderboard-grade performance at a fraction of pretraining cost, challenges the dominant scaling narrative that equates progress strictly with ever-larger monolithic pretraining runs. For ML engineers and infrastructure teams, a validated ~94% training-cost reduction would materially change cost projections for model development and might shift investments toward flexible training pipelines, elastic model families, and more aggressive subnetwork selection or post-training tuning.
Observers should look for third-party benchmark reproductions, independent inference-cost comparisons on real-world workloads, and open-source evaluation artifacts. Also watch for technical writeups or code releases that clarify the subnetwork selection criteria, the specifics of the disaggregated asynchronous RL pipeline, and any trade-offs in robustness or long-tail task handling reported by external evaluators.
Key Points
- 1Per Baidu, ERNIE 5.1 claims comparable leaderboard performance at about 6% of peer pretraining cost; independent validation is required.
- 2Industry-pattern observation: extracting optimized subnetworks from larger pretrained families can cut compute without proportional performance loss.
- 3For practitioners: validated cost reductions would lower resource barriers for foundation-model development and shift emphasis to elastic training pipelines.
Scoring Rationale
A claimed near-order-of-magnitude reduction in pretraining cost for a top-tier leaderboard model is notable for ML practitioners and infrastructure teams. The story rates high because the technique, if validated, affects cost models for model development, but independent reproduction is still pending.
Sources
Public references used for this report.
Practice interview problems based on real data
1,625 SQL & Python problems across 15 industry datasets — the exact type of data you work with.
Try 250 free problems


