AgentClinic introduces multimodal diagnostic benchmark for clinical AI
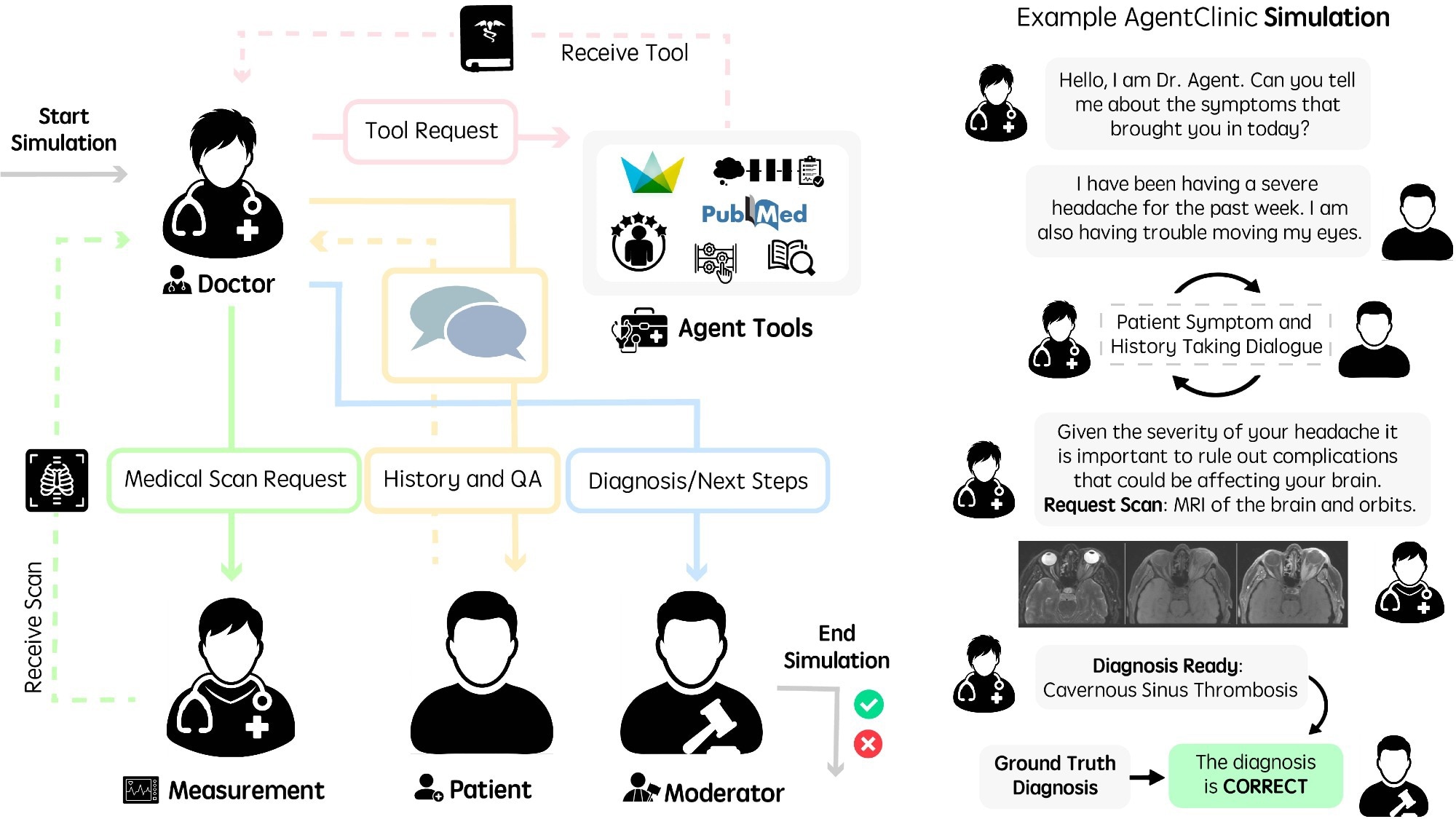
A recent study introduced AgentClinic, a multi-modal benchmark that evaluates clinical AI agents in simulated, dialogue-driven diagnostic settings, according to a News-Medical writeup. The benchmark runs four specialised agents, a measurement agent, a doctor agent, a patient agent, and a moderator, each given distinct information, and measures the doctor agent's diagnostic conclusions against ground truth, per News-Medical. The News-Medical article reports that the study's authors found that strong performance on static medical question-answering tasks was only weakly predictive of performance in AgentClinic, and that diagnostic accuracy sometimes fell sharply when cases were converted into AgentClinic's sequential format. The benchmark uses questions from the MedQA dataset based on United States Medical Licensing Exam-style cases, News-Medical reports.
What happened
A recent study introduced AgentClinic, a multi-modal agent benchmark for clinical AI agents, as reported by News-Medical. According to News-Medical, the benchmark frames clinical encounters as sequential, dialogue-driven simulations rather than static vignettes and assesses a single doctor agent's diagnostic output against ground truth using a moderator agent.
Design details
Per News-Medical, AgentClinic composes four role-specific agents with unique instruction sets and asymmetric information:
- •a measurement agent,
- •a doctor agent (the evaluated model),
- •a patient agent,
- •a moderator that compares conclusions to ground truth.
The News-Medical article states the study draws on questions from the MedQA dataset, which are based on United States Medical Licensing Exam-style cases.
Observed findings
According to News-Medical, the study's authors noted that strong performance on static medical question-answering tasks was only weakly predictive of performance in the interactive AgentClinic setting. News-Medical further reports that diagnostic accuracy in some cases "dropped sharply" after converting static cases into AgentClinic's sequential format.
Editorial analysis - technical context
Benchmarks that simulate multi-turn clinical workflows expose capabilities beyond single-shot QA, including information-gathering strategy, uncertainty handling, tool use, and multimodal interpretation. For practitioners, this implies evaluation criteria should include interaction robustness, error propagation across turns, and the ability to request targeted measurements rather than only final-label accuracy.
Industry context
Industry observers have increasingly criticised static-pass/fail exam benchmarks as insufficient proxies for deployed clinical behavior; AgentClinic, as reported by News-Medical, fits into a growing set of evaluation efforts aimed at more ecological validity. Comparable research trends emphasise multi-agent simulations and multimodal inputs to surface failure modes that single-turn tests miss.
What to watch
Observers will track whether AgentClinic is released with a public leaderboard or reference implementations, how broadly researchers adopt its sequential case conversions from existing datasets like MedQA, and whether performance gaps persist across models and modalities when evaluated in interaction-driven scenarios.
Key Points
- 1AgentClinic evaluates dialogue-driven clinical workflows, revealing static exam success often overestimates interactive diagnostic performance.
- 2The benchmark uses four asymmetric agents and USMLE-style cases from MedQA, exposing multimodal, sequential decision demands.
- 3For practitioners, interaction-focused evaluation highlights the need to test information-gathering, uncertainty handling, and tool integration separately.
Scoring Rationale
AgentClinic advances evaluation methodology by simulating dialogue-driven clinical workflows, a notable development for model validation. The story is a solid research contribution with practical implications for clinical-model testing but not a paradigm-shifting release.
Sources
Public references used for this report.
Practice with real Health & Insurance data
90 SQL & Python problems · 15 industry datasets
250 free problems · No credit card
See all Health & Insurance problems