
Summarized Audio Version
Introduction: A New AI Milestone
The world has been buzzing about Large Language Models (LLMs) for a while, and it sometimes feels like every day brings a new advancement—be it better chatbot capabilities or more extensive language coverage. But there’s another emerging paradigm on the horizon: Large Concept Models (LCMs), introduced by Meta. These models shift away from token-based generation toward higher-level “concept” understanding, offering a different way to tackle natural language, imagery, and even speech.
This article serves as a comprehensive yet accessible guide to LCMs:
- We’ll break down what LCMs are and how they differ from LLMs.
- We’ll explore the architecture details (like SONAR embeddings) described in Meta’s research paper.
- We’ll look at practical use cases, performance insights, and how to get started using Meta’s open-source GitHub repository.
If you’re fascinated by the trajectory of AI—or want to see how a concept-based model can expand the boundaries of machine understanding—keep reading. By the end, you’ll have a solid grasp of why LCMs are garnering attention and how you might incorporate them into your own projects.
What Makes Large Concept Models Unique?
According to Meta’s research paper, Large Concept Models focus on higher-level semantic representations rather than low-level tokens. Instead of predicting words (or subwords) in a text, an LCM attempts to capture the overarching idea of a sentence or concept across different modalities like text, images, and even speech.
Key traits include:
- Concept-Level Processing: Rather than going word by word, LCMs think in terms of entire sentences (or “concepts”).
- Multilingual & Multimodal: They rely on a system called SONAR embedding, which supports up to 200 languages in text and 57 languages in speech.
- Expanded Reasoning: By focusing on concepts, LCMs may capture more abstract relationships across domains.
“The LCM operates on an explicit higher-level semantic representation, which we name a ‘concept.’ Concepts are language- and modality-agnostic and represent a higher level idea.”
— Meta’s LCM GitHub Repository
This signals a tangible shift in how AI can interpret, store, and manipulate meaning.
LCM vs. LLM: A Quick Comparison
To see what sets LCMs apart, consider how Large Language Models (e.g., GPT) process text at the token level, predicting the next piece of text based on previous context. LCMs, by contrast, look at entire sentences or blocks of meaning, then reason about these “concepts.”
Below is a snapshot comparison:
| Aspect | Large Language Models | Large Concept Models |
|---|---|---|
| Granularity | Token-level predictions (words/subwords) | Concept-level (sentences, higher-level ideas) |
| Input Modality | Primarily text | Text, images, speech (multimodal) |
| Core Mechanism | Predicts next token in sequence | Predicts next concept embedding in a unified semantic space |
| Language Support | Often limited to dozens of languages | Up to 200 languages in text, 57 in speech (via SONAR) |
| Strengths | Flexible text generation, well-known ecosystem | Multilingual, potential for more coherent, domain-spanning reasoning |
By tackling entire sentence embeddings, LCMs can sometimes skip repetitive or low-level details that plague token-based systems, potentially improving coherence and multilingual performance.
Diving Into the Architecture
LCMs revolve around a few critical components (as detailed in Meta’s research paper and GitHub repo):
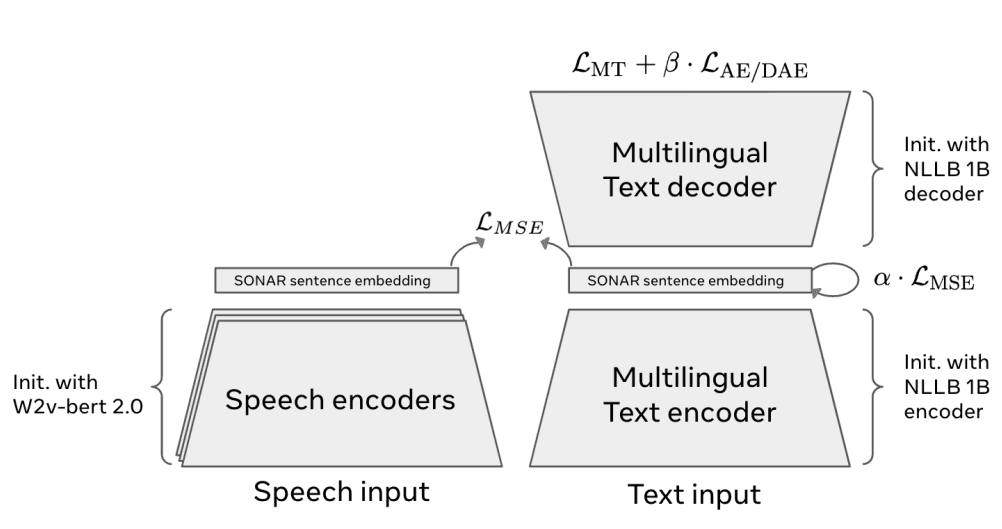
Source: LCM Research Paper
- SONAR Embeddings
- A universal embedding space that can handle up to 200 languages for text and 57 languages for speech.
- Sentences (rather than tokens) are mapped into a fixed-size vector.
- Concept-Level Modeling
- The “Large Concept Model” itself does auto-regressive prediction but at the sentence-embedding level.
- The paper outlines two main approaches:
- Base MSE LCM – Uses a mean-squared-error regression approach to predict the next concept embedding.
- Two-Tower Diffusion LCM – Employs a diffusion-based technique for more robust concept generation.
- Quantized SONAR (Coming Soon)
- The GitHub repository hints at upcoming models that use quantized embeddings, suggesting potential efficiency gains.
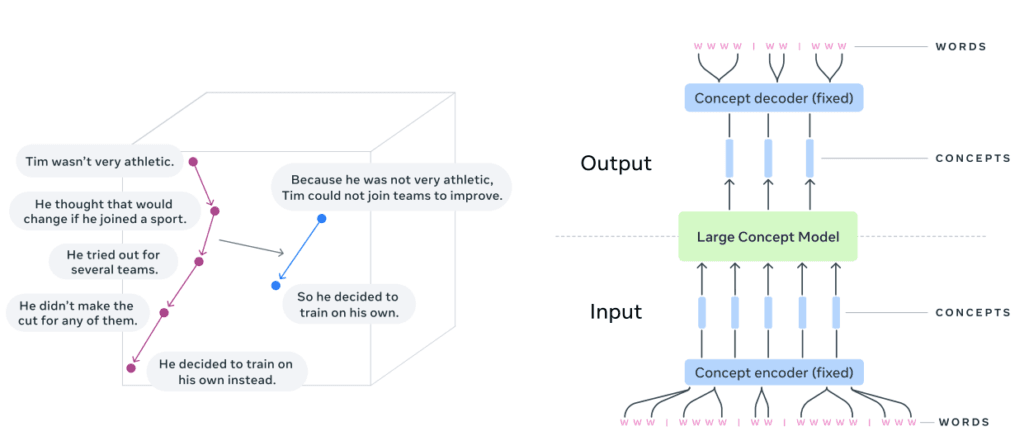
Right: fundamental architecture of an Large Concept Model (LCM).
⋆concept encoder and decoder are frozen.
Source: LCM Research Paper
Tip: If you plan on training or fine-tuning an LCM, keep your dat already split into sentences. Because LCMs operate at a sentence level, consistent segmentation can lead to better embeddings in SONAR.
Implementation & Approach: Insights from the GitHub Repo
Meta’s official GitHub repository for LCM provides end-to-end recipes for:
- Data Preparation (with an example script called
prepare_wikipedia.py) - Training (supports local training or HPC cluster setups)
- Evaluation (for generating predictions and scoring model outputs, including ROUGE metrics)
Below, we’ll highlight some of the critical pieces.
1. Installation & Environment
The GitHub repo uses fairseq2 and offers two main installation options:
- Using UV: A straightforward approach where you run
uv sync --extra cpu --extra eval --extra datato manage dependencies. - Using Pip: Requires you to install
fairseq2manually before adding the LCM repository.
For GPU usage, you must ensure you install the correct version of PyTorch (torch==2.5.1 with cuda 1.21, for example) and an appropriate variant of fairseq2.
2. Data Preparation
The pipeline typically expects sentence-level data. A sample script, prepare_wikipedia.py, demonstrates:
- Pulling text from Hugging Face or other sources,
- Splitting it into sentences,
- Encoding each sentence with SONAR embeddings.
“We provide a sample processing pipeline… Check out the file for more details on processing your own data. While the script provides an example pulling data from huggingface, we also provide APIs to process JSONL, Parquet and CSV.”
— LCM GitHub Repository
Datacards in YAML format specify the dataset’s location and schema, which helps the trainer know where to find the pre-processed embeddings.
3. Training Variants
The repository details a few training “recipes” that you can invoke with Python scripts:
- Base MSE LCM: A simpler approach that uses mean-squared error regression to predict the next concept embedding.
- Two-Tower Diffusion LCM: Splits encoding and generation logic across two networks, employing a diffusion mechanism for more stable concept generation.
Each recipe includes recommended HPC cluster specs, but you can override them for local training with fewer GPUs. Checkpoints (e.g., at step_2000, step_250000) get saved automatically in a structured folder containing logs and model configs.
4. Fine-Tuning & Evaluation
If you want to adapt a pre-trained LCM to a specific domain (e.g., summarizing legal documents), you can:
- Copy the checkpoint’s
model_card.yaml. - Register it under a custom name in your project.
- Run the
finetunescript referencing that model.
Evaluation involves generating predictions and scoring them. For instance, the command line might specify how many sentences the model should generate ("max_gen_len": 10) and how aggressively to decode these embeddings.
Warning: While LCMs can excel at concept-level reasoning, they are resource-intensive, especially if you plan to fine-tune on large, multimodal datasets. Ensure you have the proper hardware and well-annotated data to avoid skewed or truncated results.
Practical Use Cases
A. Multilingual Chatbots
Because LCMs operate in a language-agnostic embedding space, you could build a chatbot that instantly supports dozens (or hundreds) of languages, often without re-training separate models for each one.
B. Cross-Domain Analytics
Imagine an LCM ingesting text, images, and even short audio clips. This opens the door to advanced product analysis—identifying, for instance, how user reviews, product images, and tutorial videos correlate with user satisfaction.
C. Summarization & Document Understanding
Due to sentence-level reasoning, LCMs might generate more coherent and concise summaries, especially for long documents. Preliminary experiments from Meta’s team indicate better coherence in summary tasks compared to some LLM baselines (though this can vary by domain and data quality).
Performance & Experiments: Key Takeaways
From the paper’s reported results:
- MSE LCM vs. Two-Tower Diffusion: Diffusion-based approaches generally showed better concept generation stability.
- Multilingual Gains: LCMs displayed strong performance across languages, including those traditionally considered low-resource.
- Scaling Behavior: Operating at a concept level means the effective sequence length is much shorter than token-based approaches, potentially improving performance on very large contexts.
Still, LLMs remain strong for purely text-based tasks. LCMs shine when bridging multiple types of data or when you need conceptual leaps that aren’t easily captured at the token level.
Table: LCM Variants at a Glance
| LCM Variant | Description | Pros | Cons |
|---|---|---|---|
| Base MSE LCM | Predicts the next concept embedding using a mean-squared error loss. | Simpler to implement. Less computationally heavy. | May be less accurate on complex, multi-step reasoning. |
| Two-Tower Diffusion LCM | Employs diffusion-based approach with separate towers for encoding and generating embeddings. | More robust concept generation. Higher quality outputs. | Additional complexity in training. |
| Quantized SONAR (Upcoming) | Encodes sentence embeddings using a quantized representation for efficiency. | Could significantly reduce storage overhead. | Not yet fully released/experimentally validated. |
Tips for Success with LCM
- Ensure High-Quality Sentence Splits: Since LCMs revolve around sentences, poorly segmented data can degrade the model’s conceptual representation.
- Use Diverse Data: For truly robust concept learning, feed the model a wide range of text, images, or speech from various domains.
- Leverage Built-In Scripts: The official GitHub’s scripts (
prepare_wikipedia.py, training recipes) can save time and reduce the risk of setup errors.
Tip: If you plan on training or fine-tuning an LCM, keep your dat already split into sentences. Because LCMs operate at a sentence level, consistent segmentation can lead to better embeddings in SONAR.
Potential Challenges and Future Directions
LCMs are not a silver bullet. They still face hurdles:
- Continuous vs. Discrete Generation: Predicting embeddings (continuous numbers) can be trickier to control than discrete tokens.
- Computational Resources: Handling extensive embeddings, especially in diffusion-based models, demands powerful GPUs (and possibly HPC clusters).
- Domain Adaptation: While concept-level reasoning is powerful, specialized domains (legal, medical) may require careful fine-tuning.
According to the paper and GitHub, upcoming directions include:
- Quantized Embeddings for more efficient memory usage.
- Expanded Modality Support so the model can handle even more data formats.
- Better Normalization Techniques to ensure stable training across large-scale corpora.
Conclusion: Why LCMs Matter
In essence, Large Concept Models present an exciting progression from token-based LLMs. By focusing on higher-level “concepts”—entire sentences, ideas, and relationships—LCMs could:
- Enhance multilingual performance beyond what we see in standard LLMs,
- Streamline large-context tasks by reducing the effective sequence length,
- Blend multiple data types (text, images, speech) into a unified reasoning process.
Whether you’re exploring advanced analytics, designing a multilingual assistant, or simply passionate about the future of AI, LCMs show that there’s more to language understanding than predicting the next word. This new framework invites a broader, more conceptual approach that might better match how humans actually think and communicate.
Final Thoughts & Next Steps
- Read the Paper: If you haven’t yet, dive into the official Meta research paper for in-depth technical details.
- Explore the GitHub: Check out the LCM repository to see sample data pipelines, training scripts, and evaluation tools.
- Experiment Locally: Start small by training or fine-tuning a 1.6B parameter MSE LCM on a localized dataset, then scale up.
- Watch for Updates: Keep an eye out for the quantized SONAR space release, which could make LCMs more practical for larger deployments.
By integrating the best practices from both the paper and the GitHub repository, you’ll be well on your way to leveraging LCMs for a new wave of AI innovation—one that goes beyond the usual token-level conversation and into the realm of true conceptual understanding.


