-

EARLY DEVELOPMENTS IN FIELD OF LIGHT AND VISION (1700S - 1900S)
From early 1700S till 1900S one of the fields that was fascinated amongst the scientific community was light and its behaviour, from understanding the principles of light and vision, to using photography to study motion of stars, till creating the first camera system in 1884 by Kodak. All early developments in the field of vision were done during this period. -

1957 : First Digital Image scanner
The first known digital image scanner, as we understand it today, was the "Cyclograph" developed by Dr. Russell A. Kirsch and his team by transforming images into grids of numbers.Kirsch and his colleagues at NBS, who had developed the nation's first programmable computer, the Standards Eastern Automatic Computer (SEAC), created a rotating drum scanner and programming that allowed images to be fed into it. The first image scanned was a head-and-shoulders shot of Kirsch's three-month-old son Walden.Resource: First Digital Image
-
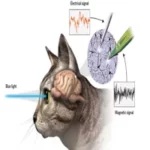
1962 : VISUAL CORTEX ( David Hubel and Torsten Wiesel )
David Hubel and Torsten Wiesel conducted groundbreaking research on the structure and function of the visual cortex, particularly in cats and later primates. Their work revealed the presence of neurons responsible for detecting edges and orientation in the visual field.Their research significantly influenced our understanding of how the visual system processes information and has had a substantial impact on the development of computer vision algorithms inspired by the human visual system.Paper: functional architecture in the cat's visual cortex
-

1963 : Machine Perception of Three-Dimensional Solids
Commonly referred to as father of computer vision Larry Roberts presented his thesis on Machine Perception of Three-Dimensional Solids at MIT on June 1963 laying one of the foundations in the field.This thesis explored methods for understanding three-dimensional objects from two-dimensional images, which is a foundational concept in computer vision.Paper: Machine Perception of Three-Dimensional Solids
-

1966 : summer vision project
This is the year when first summer vision project at MIt took place, With a goal to identify different segments of a picture and classify them. The main objective was to identify objects, background and chaos in the pictures.Paper: The Summer Vision Project
-

1967 : The Secret History of Facial Recognition
In their thesis in IEEE computer conference in 1967 Woodrow W. Bledsoe and I. Kanter presented their research which used a combination of edge detection and feature matching to recognize human faces. It was one of the first successful computer vision systems to be developed for face recognition.Wiki: Facial Recognition System Resource: The Secret History of Facial Recognition
-

1968 : Sword of Damocles
The Sword of Damocles was an early head-mounted display system that combined computer-generated graphics with the real world, creating a rudimentary form of AR. Developed in 1968 at Harvard by computer scientist Ivan Sutherland.Resource: A head-mounted three dimensional display
-

1972 : Hough Transform
The Hough transform was developed by Richard Duda and Peter Hart. The method is widely used for detecting simple geometric shapes like lines and circles in images.The key idea behind the Hough Transform is to represent each edge point not in the image space (x, y) but in a parameter space (usually represented as ρ (rho) and θ (theta)).Wiki: Hough Transform Resource: USE OF THE HOUGH TRASFORMTION TO DETECT LINES AND CURVES IN PICTURES
-

1973 : pictorial structures
The concept of "pictorial structures" was introduced by Michael A. Fischler and Robert A. Elschlager, in their paper "The Representation and Matching of Pictorial Structures" which is a significant contribution in the field of computer vision. The study they conducted was aimed to find objects in pictures based on information provided.Paper: The Representation and Matching of Pictorial Structures
-

1980 : Automatix
Automatix, Inc. was a company that played a pioneering role in the field of industrial automation and computer vision. It was founded in the early 1980s and specialized in developing computer vision and robotic systems for various industrial applications. Automatix is particularly notable for its work in the integration of computer vision technology into manufacturing processes.Their system was used for tasks such as quality control and inspection in manufacturing, including the inspection of electronic components for defects.Wiki: Automatix Inc.
-

1980 : NeoCognitron
The Neocognitron is a neural network model for pattern recognition and image processing, developed by Kunihiko Fukushima in the 1980s. It's an early form of a convolutional neural network (CNN) and played a significant role in the history of deep learning and computer vision. One of its key contributions is the ability to recognize patterns regardless of their position or orientation in the input image.Wiki: Neocognitron Paper: Neocognitron: A self-organizing neural network
-

1981 : RanSAC
The RANSAC algorithm was i introduced by Martin A. Fischler and Robert C. Bolles in their paper "Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography" in 1981. The Algorithm majorly focuses on Location determination problem, to identify a point in space based on certain predetermined locations.Wiki: Random Sample Consensus Paper: Random Sample Consensus: A Paradigm for Model Fitting
-

1981 : Lucas-Kanade Optical Flow algorithm
The Lucas-Kanade Optical Flow algorithm was introduced by Bruce D. Lucas and Takeo Kanade.it is used to estimate the motion of objects or points in a sequence of images or video frames. It works by analyzing the apparent motion of pixels or features between consecutive frames to determine the direction and speed of the movement.Wiki: Lucas–Kanade Method Paper: An Iterative Image Registration Technique with an Application to Stereo Vision
-

1983 : Vision By David Marr
David Marr published the book Vision. This book provides a comprehensive theoretical framework for understanding vision and has had a significant impact on the field of computer vision and visual perception.Book: Vision
-

1986 : 3D shape recovery from images
Horn and Brooks published a paper titled "The variational approach to shape from shading," which indeed addressed the problem of 3D shape recovery from images using shading information. They also worked on stereo vision, which involves using multiple viewpoints to estimate 3D shape.Paper: The variational approach to shape from shading
-

1987 : Deriche edge detector
The Deriche edge detector is an edge detection technique used in computer vision and image processing. It's based on the concept of computing gradient information in an image to locate edges or boundaries between different objects or regions. The Deriche edge detector is a recursive filter designed to find edges while suppressing noise in the image.Paper: Using Canny's criteria to derive a recursively implemented optimal edge detector
-

1988 : Active contour Model
ACM was introduced by Michael Kass, Andrew Witkin, and Demetri Terzopoulos. Active Contour Models, often referred to as "Snakes," are a class of computer vision models used for image segmentation and boundary detection. These models are particularly useful for finding and delineating object boundaries or contours within images.Wiki: Active Contour Model Paper: Snakes: Active contour models
-

1989 : Mumford–Shah functional
It is a mathematical model used for image segmentation and restoration. The function is particularly useful for segmenting images into distinct regions while preserving important edges and boundaries. It is used to address the problem of piecewise constant approximation of images, which means dividing an image into regions where the intensity or color is approximately constant.Wiki: Mumford Shah Functional Resource: Optimal Approximations by Piecewise Smooth Functions and Associated Variational Problems
-

1991 : Eigenfaces algorithm
The Eigenfaces algorithm was developed by Matthew Turk and Alex Pentland, and it is a well-known facial recognition method based on principal component analysis (PCA).The heart of the Eigenfaces algorithm is the creation of a set of "eigenfaces." These eigenfaces are essentially a set of eigenvectors derived from the covariance matrix of the preprocessed facial images. Each eigenface represents a particular pattern or feature that is common in the dataset.Wiki: EigenFace Paper: Face Recognition Using Eigenfaces
-

1993 : Scale-space blob detection
Introduced by Tony Lindeberg, it is a method for detecting blob-like structures in images at various scales. It is essential for object recognition and shape analysis.It forms the basis for various feature detection and extraction techniques used in computer vision.Paper: Detecting salient blob-like image structures and their scales with a scale-space primal sketch
-

1999 : BlobWorld
Introduced by Michael Carson in his paper titled "Blobworld: A System for Region-Based Image Indexing and Retrieval." This paper was published in 1999 and presents the Blobworld framework, which is designed for region-based image indexing and retrieval. It focuses on the detection and representation of regions (blobs) in images for image analysis and retrieval.Paper: Blobworld: A System for Region-Based Image Indexing and Retrieval
-

1999 : SIFT
The SIFT (Scale-Invariant Feature Transform) algorithm is a computer vision and image processing technique used for detecting and describing local features in images. SIFT is known for its robustness to various image transformations, such as scaling, rotation, and changes in viewpoint, making it a valuable tool for tasks like object recognition, image stitching, and more.Wiki: Scale-Invariant Feature Transform Paper: Object Recognition from Local Scale-Invariant Features
-

2000 : OPenCv
Open Source Computer Vision Library, is an open-source computer vision and machine learning software library developed by Intel. With the initial alpha version launch in 2000,OpenCV offers functions for a wide range of image processing tasks, including filtering, edge detection, and geometric transformations.Known for its real-time capabilities, it is suitable for applications like video analysis, robotics, and augmented reality. -

2001 : Haar Cascades
Haar Cascades, also known as Haar-like features and Haar Cascade Classifiers, are a machine learning object detection method used to identify objects in images or video. They were developed by Paul Viola and Michael Jones and were introduced in the early 2000s. Haar Cascades are particularly well-known for their efficiency in detecting faces but can be used for a variety of object recognition tasks.Wiki: Haar Like Feature Paper: Rapid object detection using a boosted cascade of simple features
-

2004 : Voila Jones Face Detection Model
The Viola-Jones face detection model, was developed by Paul Viola and Michael Jones, is a pioneering and influential approach for detecting faces in images and videos. This model is known for its efficiency and high accuracy, making it one of the early real-time face detection systems.Paper: TRobust Real-Time Face Detection
-

2005 : HOG (Histogram of Oriented Gradients)
First introduced in 1986 by Robert K. McConnell. Later The Histogram of Oriented Gradients (HOG) algorithm was introduced by Navneet Dalal and Bill Triggs, is a feature descriptor used for object detection. It calculates histograms of gradient orientations in image regions, making it effective for tasks like human detection and object recognition.Wiki: Histogram of oriented gradients Paper: Histograms of oriented gradients for human detection
-

2005 : VSLAM
Visual SLAM (Simultaneous Localization and Mapping) is a subset of SLAM that relies on visual data, typically from cameras, to build maps of an environment and estimate the device's position within that environment.The algorithm determines the device's position and orientation (pose) relative to the map it is building. This is done by matching observed features with the features in the map.Paper: The vSLAM Algorithm for Robust Localization and Mapping
-

2006 : speeded-Up Robust Features (SURF)
Developed by Herbert Bay, Tinne Tuytelaars, and Luc Van Gool, is a feature detection and description algorithm in computer vision.The SURF algorithm consists of interest point detection, local neighborhood description, and matching for efficient and robust feature detection and matching in computer vision.Wiki: Speeded up robust features Paper: SURF: Speeded Up Robust Features
-
2007 : PCBR
A Principal Curvature-Based Region (PCBR) Detector is a computer vision and image processing technique used to identify and segment regions of interest in an image based on the local principal curvature properties. It is a structure-based detector, which means that it is not affected by changes in local intensity. PCBR detectors have been shown to be effective for a variety of tasks, including object detection, image segmentation, and medical image analysis.Wiki: Principal curvature-based region detector Paper: Principal Curvature-Based Region Detector for Object Recognition
-
2009 : VOC
The PASCAL VOC (Visual Object Classes) and ImageNet competitions were introduced to advance object recognition in computer vision by providing large-scale datasets and benchmark challenges. These competitions indeed played a crucial role in driving advancements in computer vision algorithms, particularly in the field of object recognition and classification.Paper: The PASCAL Visual Object Classes (VOC) Challenge
-

2010 : Kinetic Sensor
Microsoft Released The Kinect sensor in 2010.It combined RGB (color) and depth information to enable real-time 3D object recognition and tracking. It marked a significant milestone in the field of gesture recognition, human-computer interaction, and computer vision. -

2010 : ILSVRC
ILSVRC stands for the "ImageNet Large Scale Visual Recognition Challenge." It is an annual competition in the field of computer vision and image recognition. ILSVRC focuses on large-scale image classification and object detection tasks. mageNet was one of the earliest large-scale image datasets.The competition typically involved challenges like image classification and object detection, where participants had to develop algorithms and models to correctly classify objects within images.Resource: ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
-

2012 : AlexNet
AlexNet is a deep convolutional neural network architecture designed for image classification. It was developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton and was the winning entry in the ImageNet Large Scale Visual Recognition Challenge in 2012. AlexNet is significant in the history of deep learning and computer vision due to its success in image classification tasks.Wiki: AlexNet Resource: ImageNet classification with deep convolutional neural networks
-

2014 : COCO Data set
Microsoft Common Objects in Context (COCO) dataset was indeed introduced in 2014 and has become a prominent dataset in the field of computer vision. It is known for its diversity of object categories and complex scenes, making it a valuable resource for various computer vision tasks, including object detection, image segmentation, and image captioning.Resource: Coco Dataset
-
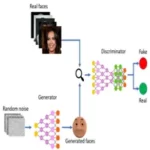
2014 : GAN’s
A Generative Adversarial Network, or GAN, is a deep learning framework that consists of two neural networks, the generator and the discriminator, which are trained simultaneously through a competitive process. GANs were introduced by Ian Goodfellow and his colleagues in 2014 and have since become a powerful tool for generating data, particularly in the domain of computer vision.Wiki: Generative adversarial network Paper: Generative Adversarial Nets
-

2014 : VGG
VGG is one of the classic deep learning architectures that has been widely used in computer vision tasks, particularly in image classification. Although it is not the most modern architecture, it is still used for educational purposes and as a baseline for various vision-related tasks. The simplicity of the architecture and its effectiveness make it a useful reference in computer vision.Paper: Very Deep Convolutional Networks for Large-Scale Image Recognition
-

2015 : SMPL
The Skinned Multi-Person Linear (SMPL) model is a widely used and influential model in the field of computer graphics, computer vision, and computer-aided design. It is primarily used for modeling and animating the human body in a realistic and efficient manner.SMPL relies on the concept of linear blend skinning to represent how the 3D mesh of the human body deforms as it moves. This means that the model captures how the skin and underlying skeleton interact and deform in a way that's easy to compute and animate.Paper: SMPL: a skinned multi-person linear model
-

2015 : DeepDream
Deepdream was introduced by google created by Google engineer Alexander Mordvintsev, it is a convolutional neural network method to enhance and modify images in a unique and psychedelic way. DeepDream operates iteratively, enhancing and exaggerating the patterns or features that the neural network recognizes. This process is called "dreaming." The deeper layers of the neural network tend to recognize more complex and abstract features, resulting in visually surreal and intricate images.Wiki: DeepDream Resource: DEEP DREAM GENERATOR
-

2015 : Neural Style Transfer
Neural style transfer is a deep learning technique that combines the content of one image with the artistic style of another. It uses convolutional neural networks to extract features from the content and style images and defines a loss function to minimize the difference between them. The optimization process adjusts the pixel values of a generated image to strike a balance between content and style, resulting in visually striking and artistic images that blend recognizable content with distinctive artistic styles.Wiki: Neural style transfer Paper: A Neural Algorithm of Artistic Style
-

2015 : Faster R-CNN
Is a deep learning-based object detection framework that was introduced in 2015 by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. It builds upon the R-CNN (Regions with Convolutional Neural Networks) family of models but significantly improves their speed and accuracy.Faster R-CNN introduced the concept of region proposal networks, which significantly improved the speed and accuracy of object detection by integrating deep learning techniques.Wiki: Region Based Convolutional Neural Networks Paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
-

2017 : OpenPose
OpenPose is a computer vision system designed for real-time multi-person keypoint detection, with a primary focus on human pose estimation. It was developed by the CMU Perceptual Computing Lab and introduced in 2017.Used to identify and locate key body parts and joints in images or video frames. It can determine the positions of various body parts like the head, torso, arms, and legs and establish the connections between them to create a skeleton-like representation.Paper: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields
-

2017 : Mask R-CNN
Mask R-CNN is an extension of the Faster R-CNN object detection framework, and it was developed in 2017 by Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN is primarily used for instance segmentation, allowing it to detect objects in images and also provide detailed pixel-level masks for each individual object, thereby segmenting them with high precision. It's a powerful tool for various computer vision tasks that require detailed object segmentation.Paper: Mask R-CNN
-

2018 : YOLO V3
You Look Only Once Initially introduced by Joseph Redmon and Ali Farhadi in 2015. The YOLO v3 was released in 2018. YOLO v3 offered real-time object detection capabilities, which was a game-changer. It enabled applications like autonomous vehicles and video surveillance systems to process and interpret visual data at high speeds.YOLO's "single shot" approach, processing an entire image in one pass, dramatically improved efficiency and speed compared to traditional two-stage object detection systems.Paper: YOLOv3: An Incremental Improvement
-

2019 : EfficientNet
EfficientNet, on the other hand, is a more recent architecture designed to strike a balance between model accuracy and computational efficiency. It has gained popularity due to its superior performance on image classification tasks and its efficiency, which makes it suitable for various real-world applications. EfficientNet models are often used in scenarios where computational resources are limited or when efficient deployment on edge devices is required.Paper: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
-

2020 : VIT ( Vision Transformers )
Vision Transformers (ViTs) are a class of deep learning models that apply the Transformer architecture, which was originally designed for natural language processing. In Vision Transformers, images are divided into fixed-size non-overlapping patches. Each patch is treated as a sequence of tokens, just like words in a sentence in NLP tasks.Wiki: Vision transformer Paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
-

2020 : GPT-3 and Vision-Language Models 2020
GPT-3, developed by OpenAI, is a large language model known for its natural language processing capabilities. While it was primarily designed for text-related tasks, it has been shown to be versatile and applicable to vision-language tasks as well.It demonstrated the versatility of large language models for vision-language tasks, allowing the generation of natural language descriptions from images.