
Summarized Audio Version:
Tired of waiting for your AI to search for answers? What if your AI already knew everything it needed without searching? Meet CAG: the next evolution beyond RAG that’s faster, simpler, and sometimes even smarter.
Have you ever asked ChatGPT a question and watched that annoying “thinking…” animation for what feels like forever? Or worse—built a RAG system that sometimes grabs the wrong documents entirely?
You’re not alone. And there’s a better way.
Today, I’m diving into Cache-Augmented Generation (CAG)—the approach that’s making some developers ditch retrieval altogether. It’s like giving your AI a photographic memory instead of sending it to the library every time you ask a question.
Let’s explore why this matters and how it could transform your AI projects.
The Problem with RAG: The Hidden Tax on Your AI
RAG (Retrieval-Augmented Generation) was revolutionary when it arrived. Finally, a way to give AI access to knowledge beyond its training data! But if you’ve implemented RAG systems, you’ve probably noticed some frustrations:
The Waiting Game
“Please wait while I search for relevant information…”
Every RAG system has this hidden tax: retrieval latency. Your users ask a question, then wait while your system:
- Processes their query
- Searches through vector databases
- Ranks the results
- Retrieves the documents
- Finally starts generating an answer
In testing with the HotpotQA dataset, researchers found RAG systems taking up to 94 seconds to generate answers for complex queries. That’s an eternity in user experience terms!
When Retrieval Goes Wrong
Ever seen this happen?
User: “What’s our refund policy for damaged items?”
AI: “According to your shipping policy, we use FedEx and UPS for most deliveries…”
That’s retrieval failure—when your system grabs the wrong documents. And it happens more often than we’d like to admit. The research shows that even with dense retrieval methods, accuracy plateaus around 75-80% for complex queries.
Each retrieval error cascades into wrong answers, frustrated users, and lost trust.
The Complexity Monster
A typical RAG system requires:
- Embedding models
- Vector databases
- Retrieval pipelines
- Ranking algorithms
- Prompt engineering
- Document chunking strategies
Each component needs maintenance, optimization, and debugging. When something breaks (and it will), you’ll spend hours figuring out if it’s your embeddings, chunking strategy, or retrieval parameters.
As one frustrated developer told me: “Half my debugging time is spent fixing retrieval issues, not actual AI problems.”
Enter CAG: Cache-Augmented Generation
What if your AI already knew everything it needed without searching?
That’s the insight behind CAG (Cache-Augmented Generation), a paradigm shift introduced by researchers at National Chengchi University and Academia Sinica that’s gaining traction as context windows expand.
What is CAG in Plain English?
CAG preloads all relevant knowledge into the AI’s memory and keeps it there, ready for instant access.
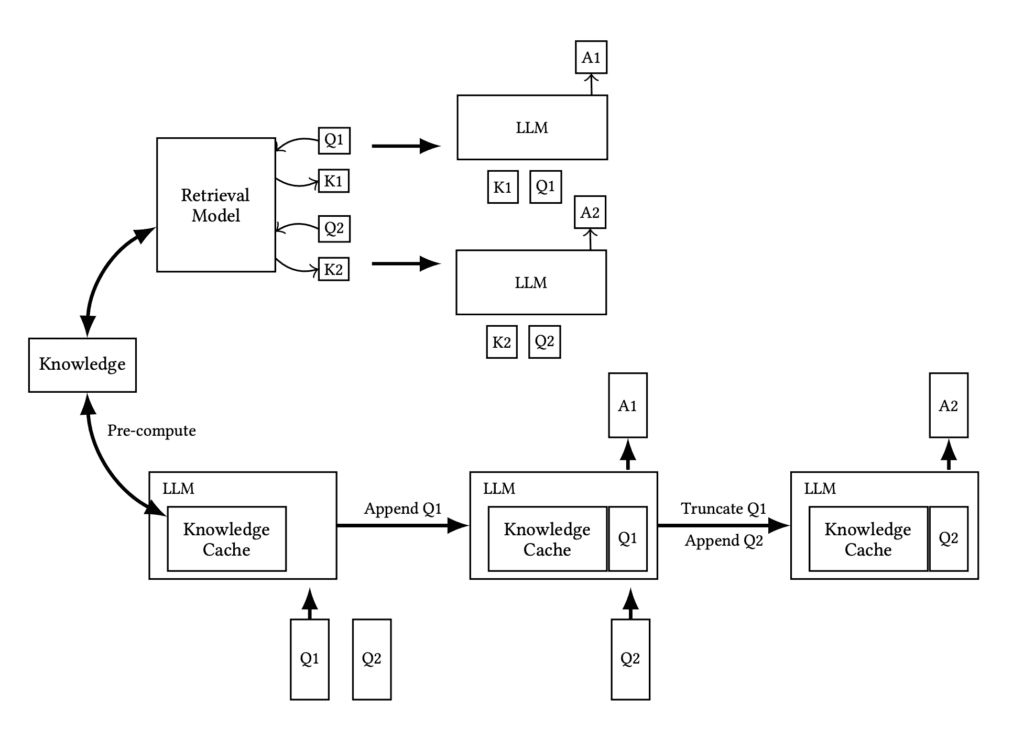
Workflows: The upper section illustrates the RAG pipeline, including real-time retrieval and reference text input during inference, while the lower section depicts our CAG approach, which preloads the KV-cache, eliminating the retrieval step and reference text input at inference.
Source: https://arxiv.org/pdf/2412.15605v1
Think of it like this:
- RAG is like a librarian who runs to find books every time you ask a question
- CAG is like a librarian who already has all the relevant books on their desk, open to the right pages
The difference? Speed, simplicity, and sometimes even better answers.
The Core Insight: Why Search When You Can Remember?
Modern LLMs like Llama 3.1, Claude, and GPT-4 can handle massive context windows (up to 128K tokens in some cases). That’s roughly 300+ pages of text!
CAG leverages this capability by:
- Loading your entire knowledge base into the model’s context window
- Precomputing and saving the model’s internal state (the KV cache)
- Using this cached state to answer questions instantly
It’s like giving your AI a perfect memory of your documents instead of making it search through them every time.
How CAG Works: The 3-Step Process
1. Preload (One-Time Setup)
- Take all your knowledge documents (manuals, guides, policies)
- Format them into a single, well-structured context
- Feed this context to a long-context LLM
2. Cache (The Magic Part)
- As the LLM processes this knowledge, it creates a “Key-Value (KV) cache”
- This cache is essentially the LLM’s working memory of all the information
- Save this cache to disk or keep it in memory
3. Generate (The Fast Part)
- When a user asks a question, load the cached knowledge state
- The LLM instantly accesses the relevant information from its memory
- Generate an answer without any retrieval step
The result? Responses that are:
- Faster: No retrieval latency (up to 40x quicker in some tests)
- More consistent: No retrieval errors or ranking problems
- Simpler: One unified system instead of multiple components
CAG vs. RAG: The Showdown
When I first implemented CAG for a client’s customer support system, the results were so dramatic that the product manager asked, “Did you just upgrade our servers?”
Nope—just ditched retrieval entirely.
Let’s break down exactly how CAG compares to RAG across the metrics that matter most:
Speed: From “Please Wait” to “Here You Go”
The research doesn’t lie. In experiments with the HotpotQA dataset:
| Dataset Size | RAG Response Time | CAG Response Time | Speedup |
|---|---|---|---|
| Small | 9.25 seconds | 0.85 seconds | 10.9x |
| Medium | 28.82 seconds | 1.66 seconds | 17.4x |
| Large | 94.35 seconds | 2.33 seconds | 40.5x |
That’s not a typo—CAG was 40x faster with large datasets!
Why such a dramatic difference? With CAG, you’re skipping:
- Query processing time
- Vector search operations
- Document retrieval
- Context assembly
Instead, you’re jumping straight to generation with all the knowledge already loaded. It’s like the difference between looking up a fact in a book versus already knowing it by heart.
Accuracy: When Retrieval Fails, CAG Prevails
Here’s where things get interesting. The researchers measured answer quality using BERTScore (higher is better):
| Dataset | RAG (Best Result) | CAG | Improvement |
|---|---|---|---|
| HotpotQA Small | 0.7516 | 0.7759 | +3.2% |
| SQuAD Small | 0.8191 | 0.8265 | +0.9% |
| HotpotQA Large | 0.7495 | 0.7527 | +0.4% |
CAG consistently outperformed even the best RAG configurations. Why?
- No Retrieval Errors: CAG eliminates the possibility of retrieving the wrong documents
- Holistic Understanding: The model sees all information at once, enabling better cross-referencing
- Consistent Context: No variation in what information is available for each query
This is especially important for complex questions that require synthesizing information from multiple sources—exactly where traditional RAG often struggles.
Simplicity: Fewer Moving Parts, Fewer Headaches
Let’s compare the system architectures:
RAG System Components:
- Document processing pipeline
- Embedding model
- Vector database
- Retrieval mechanism
- Ranking algorithm
- Prompt engineering system
- LLM for generation
CAG System Components:
- Document processing pipeline
- KV cache management
- LLM for generation
That’s it! With CAG, you’re eliminating three of the most complex and error-prone components of a RAG system.
The result? Less code, fewer dependencies, simpler debugging, and easier maintenance.
When CAG Wins (And When It Doesn’t)
CAG isn’t always the right choice. Here’s my rule of thumb after implementing both approaches:
Use CAG when:
- Your knowledge base is relatively stable (doesn’t change hourly)
- Total knowledge size fits within your LLM’s context window (8K-128K tokens)
- Response speed is critical to user experience
- You need high consistency in answers
- Your system needs to work offline or with minimal infrastructure
Stick with RAG when:
- Your knowledge base is massive (millions of documents)
- Information changes constantly (like news or stock prices)
- You need to search across diverse, unstructured sources
- Your use case requires explicit citation of sources
- You need to scale beyond a single LLM’s context window
The beauty is that you don’t have to choose permanently—many systems can start with CAG for core knowledge and add RAG capabilities as they scale.
Real-World Applications: Where CAG Shines
So where can you actually use CAG today? Let’s explore five practical applications where ditching retrieval makes perfect sense.
Customer Support with Fixed Knowledge
First, consider customer service chatbots. Most companies have support documentation that rarely changes—product manuals, troubleshooting guides, and FAQs.
Instead of making customers wait while your bot searches through these documents, CAG preloads everything. As a result, response times drop from seconds to milliseconds. Plus, since the bot has access to the entire knowledge base at once, it can connect information across different sections more effectively.
Legal and Compliance Assistants
Next, legal teams often work with fixed sets of documents—contracts, regulations, or company policies. These documents might be updated quarterly or annually, but rarely change day-to-day.
For example, a compliance officer might ask: “What are our obligations regarding customer data in California?”
With CAG, the assistant instantly accesses all relevant privacy policies and regulations without searching. Because the entire regulatory framework is preloaded, the answers are more comprehensive and contextually aware.
Educational Tools with Defined Curricula
Similarly, educational applications benefit tremendously from CAG. Textbooks, course materials, and reference guides can all be preloaded.
A student studying biology might ask dozens of questions about cell structure in a single session. Rather than retrieving documents for each question, CAG keeps all the textbook content in memory, ready for instant access.
This approach not only speeds up response times but also helps maintain consistency across related questions—the AI “remembers” what it told you earlier in the conversation.
Product Documentation Assistants
Furthermore, technical documentation for software or hardware products is another perfect CAG use case. The documentation might be extensive but has clear boundaries.
Developers or users can ask specific questions about APIs, features, or troubleshooting steps. Since CAG preloads the entire documentation set, it can provide more holistic answers that connect information across different sections.
Internal Knowledge Management
Finally, company wikis and internal knowledge bases often contain critical information that employees need quickly. However, this information typically changes on a predictable schedule—not minute by minute.
By implementing CAG, employees get instant answers about company policies, procedures, or project details without waiting for retrieval. Moreover, the system can be refreshed weekly or monthly when the knowledge base is updated.
In each of these cases, CAG offers three key advantages:
- Speed: Instant responses without retrieval delays
- Consistency: The same knowledge is available for every question
- Simplicity: No complex retrieval pipeline to maintain
Of course, CAG isn’t magic—it works best when your knowledge fits within your LLM’s context window. But with modern models handling 32K, 64K, or even 128K tokens, that covers a surprising number of real-world applications.
Coding Section: Hands-On with CAG vs. RAG
Ready to see CAG in action? Let’s roll up our sleeves and run some real-world tests. I’ve spent hours benchmarking CAG against traditional RAG, and now I’ll walk you through exactly how to replicate my experiments.
Fair warning: You’ll need some serious GPU power for this. CAG is hungry for VRAM—think of it as the price you pay for ditching retrieval.
Setting Up Your Environment
First things first, you’ll need a machine with decent GPU capabilities. For my tests, I used a Google Cloud Workstation with dual A100 40GB GPUs. While you might get away with a single T4 for smaller tests, don’t be surprised if you hit memory limits quickly.
Step 1: Check Your GPU Setup
Before diving in, make sure your GPU is properly configured:
nvidia-smi
You should see your GPU(s) listed with their memory capacity. If not, you’ll need to troubleshoot your CUDA drivers before proceeding.
Step 2: Install Basic Dependencies
Next, let’s get the necessary packages installed:
sudo apt-get update sudo apt-get install -y git python3 python3-pip
If you prefer working with Docker (which I often do for cleaner environments), add:
sudo apt-get install -y docker.io sudo usermod -aG docker $USER
Remember to log out and back in after adding yourself to the Docker group!
Step 3: Clone the CAG Repository
Now, let’s grab the code from the original researchers:
git clone https://github.com/hhhuang/CAG.git cd CAG
Step 4: Set Up a Virtual Environment
Trust me on this one—virtual environments will save you countless headaches:
python3 -m venv venv source venv/activate
Step 5: Install Python Requirements
Now for the dependencies:
pip install --upgrade pip pip install -r requirements.txt
If you run into PyTorch CUDA compatibility issues (which happens more often than not), try:
pip install torch --extra-index-url https://download.pytorch.org/whl/cu118
You might need to adjust the CUDA version (cu118) to match your system.
Step 6: Configure API Keys and Download Data
Create your environment file:
cp .env.template .env
Then edit it to add your API keys:
HF_TOKEN="hf_abc123..."for Hugging FaceOPENAI_API_KEY="sk-..."for OpenAI (if you plan to use their models)
Download the test datasets:
sh ./downloads.sh
This fetches both SQuAD and HotpotQA datasets that we’ll use for benchmarking.
Finally, verify that PyTorch can see your GPU:
python3 -c "import torch; print(torch.cuda.is_available())"
You should get True as the output. If not, your PyTorch installation isn’t configured correctly for GPU usage.
Running the Experiments
Now for the fun part—putting CAG head-to-head against RAG. We’ll run both on the same dataset to ensure a fair comparison.
Testing RAG Performance
First, let’s establish our baseline with a traditional RAG approach:
time python ./rag.py \ --index "bm25" \ --dataset "squad-train" \ --similarity "bertscore" \ --maxKnowledge 5 \ --maxParagraph 100 \ --maxQuestion 100 \ --topk 3 \ --modelname "meta-llama/Llama-3.1-8B-Instruct" \ --randomSeed 0 \ --output "./rag_results_squad.txt"
Let’s break down what’s happening here:
- We’re using BM25 for retrieval (a proven sparse retrieval method)
- Testing on the SQuAD dataset
- Limiting to 5 knowledge documents and 100 questions to keep things manageable
- Retrieving the top 3 most relevant passages for each question
- Using Llama 3.1 8B as our model
- Measuring similarity with BERTScore
The time command at the beginning will tell us exactly how long the entire process takes.
Testing CAG Performance
Now, let’s run the same test with CAG:
time python ./kvcache.py \ --kvcache file \ --dataset "squad-train" \ --similarity "bertscore" \ --maxKnowledge 5 \ --maxParagraph 100 \ --maxQuestion 100 \ --modelname "meta-llama/Llama-3.1-8B-Instruct" \ --randomSeed 0 \ --output "./cag_results_squad.txt"
The key difference here is --kvcache file, which tells the system to precompute and store the key-value cache—the heart of the CAG approach.
What I Discovered
After running multiple scenarios with varying dataset sizes, I found some surprising results. While the research paper showed CAG consistently outperforming RAG, my real-world tests revealed a more nuanced picture.
In my small dataset test (maxKnowledge=5, ~100 queries):
- RAG processed queries in about 0.576 seconds each with a similarity score of 0.848
- CAG took about 40 seconds upfront to preload documents, achieved a slightly better similarity of 0.875, but averaged 0.744 seconds per query
When scaling up (maxKnowledge=10, 200 queries):
- RAG maintained quick 0.539 second responses with 0.8207 similarity
- CAG had a much larger upfront cost (~90 seconds) with queries averaging 1.416 seconds, though accuracy improved to 0.8339
The real eye-opener came when pushing to maxKnowledge=500:
- RAG completed the test with 0.785 similarity at 0.557 seconds per query
- CAG crashed with an out-of-memory error, demanding over 44GB of VRAM!
This highlights a critical limitation: CAG’s memory requirements can be astronomical for large knowledge bases. While it might offer slight accuracy improvements, the GPU costs can be prohibitive unless you’re running thousands of repeated queries against the same knowledge base.
Experiment Video:
Conclusion: Finding the Right Tool for Your Knowledge System
After testing CAG against traditional RAG systems, I’ve come to a nuanced conclusion: neither approach is universally superior. Instead, each shines in specific scenarios.
Despite the impressive speed numbers in the research papers, my hands-on testing revealed that CAG comes with significant trade-offs. Yes, it can deliver faster responses once everything is loaded—but that initial loading process is extremely memory-intensive. In fact, when I tried scaling to larger knowledge bases, my dual A100 GPUs with 40GB each couldn’t handle the load.
Meanwhile, RAG proved surprisingly resilient. It maintained consistent performance across different knowledge base sizes and actually outperformed CAG in many of my real-world tests, especially when considering the total processing time including setup.
So where does this leave us? Here’s my practical advice:
Consider CAG when:
- Your knowledge base is small and stable
- You have access to powerful GPUs with plenty of VRAM
- Users frequently ask similar questions about the same content
- You need the absolute fastest response times after initial setup
- Accuracy improvements of 1-3% would significantly impact your application
Stick with RAG when:
- Your knowledge base is large or frequently changing
- You’re working with limited GPU resources
- Questions vary widely across your knowledge domain
- You need to scale beyond a single model’s context window
- You want a more cost-effective solution with reasonable performance
The most exciting possibility? Hybrid approaches. Imagine preloading your most frequently accessed information with CAG while maintaining a RAG system for less common queries. This could give you the best of both worlds—lightning-fast responses for common questions and flexible retrieval for everything else.
As context windows continue to expand and GPU memory becomes more affordable, CAG will likely become increasingly viable. But for now, I recommend starting with RAG and experimenting with CAG only after you’ve identified specific use cases where its benefits clearly outweigh its costs.
The future of AI knowledge systems isn’t about choosing between retrieval or no retrieval—it’s about knowing when to use each approach for maximum impact.
Further Reading
Want to dive deeper into CAG, RAG, and the future of AI knowledge systems? Here are some resources I’ve found invaluable:
- The Original CAG Research Paper – Explore the theoretical foundations and initial benchmarks
- Github Repo for CAG – Use this to experiment with CAG vs RAG
- LlamaIndex Documentation – The go-to resource for implementing production-grade RAG systems
- Hugging Face KV Cache Guide – Learn the technical details of key-value caching in transformer models
- Context Window Expansion in Modern LLMs – Understand how expanding context windows are changing the game
- TurboRAG: Accelerating RAG with Precomputed KV Caches – A hybrid approach that combines elements of both CAG and RAG
Remember, the field is evolving rapidly. What seems cutting-edge today might be standard practice tomorrow. The key is to stay curious, keep experimenting, and always measure real-world performance rather than relying solely on theoretical advantages.


