Introduction
The Dawn of Generative AI
In recent years, Generative Artificial Intelligence (AI) has emerged as a groundbreaking force, revolutionizing how machines create content that resembles human output. From writing coherent text to generating realistic images, generative AI is at the forefront of technology, pushing the boundaries of creativity and innovation. Its impact spans various fields, including art, literature, and even software development, making it a hot topic in the data science community.
The Role of Attention Mechanisms

Source: https://arxiv.org/pdf/1706.03762.pdf
At the heart of many generative AI systems, especially those based on language models like GPT (Generative Pre-trained Transformer), lies a crucial component known as the attention mechanism. This mechanism enables the AI to focus on different parts of the input data when generating output, much like how humans pay more attention to certain aspects of a conversation while ignoring others. It’s the attention mechanism that allows AI models to generate relevant and context-aware responses, making them incredibly effective at understanding and generating human-like text.
Introducing Flash Attention
However, traditional attention mechanisms come with their own set of challenges. They are notoriously slow and consume a significant amount of memory, especially when dealing with long sequences of data. This is where Flash Attention comes into play. Designed to be both fast and memory-efficient, Flash Attention represents a monumental leap forward, addressing the inherent limitations of previous models. By optimizing how data is read and written between different levels of a GPU’s memory, Flash Attention achieves unprecedented speed and efficiency, enabling the creation of more advanced and capable AI models.
Relevance of Flash Attention
The development of Flash Attention is not just a technical achievement; it marks a pivotal moment in the advancement of generative AI. By allowing models to process information more quickly and with less memory, Flash Attention opens up new possibilities for AI applications, from more responsive AI chatbots to more sophisticated analysis of large datasets. Its impact is expected to be far-reaching, influencing not only the field of data science but also the broader landscape of technology and innovation.
Why Flash Attention?
In the rapidly evolving world of Generative AI, traditional attention mechanisms have been a cornerstone, enabling models like GPT and BERT to understand and generate human-like text. However, these mechanisms come with significant limitations, particularly in terms of computational and memory efficiency. In this section, we delve into these challenges and introduce Flash Attention as a groundbreaking solution.
Understanding the Limitations
- Computational Complexity: Traditional attention mechanisms calculate the relevance of each part of the input data to every other part. For short sequences, this is manageable. But as sequences get longer, the computations grow exponentially. Imagine trying to read a book and considering every single word’s relation to every other word; it’s overwhelming even for powerful computers.
- Memory Inefficiency: Along with the computational burden, traditional attention requires substantial memory. This is because it needs to store the relationships between all parts of the data. For large models working with extensive data sequences, this can quickly exhaust the available memory, akin to trying to remember every detail of a long story in one sitting.
These limitations hinder the development and deployment of AI models, especially for tasks requiring the analysis of large texts or complex sequences. They slow down processing times and limit the ability of models to handle longer contexts, which is crucial for generating coherent and contextually relevant outputs.
Introducing Flash Attention as a Solution

Understanding the Image:
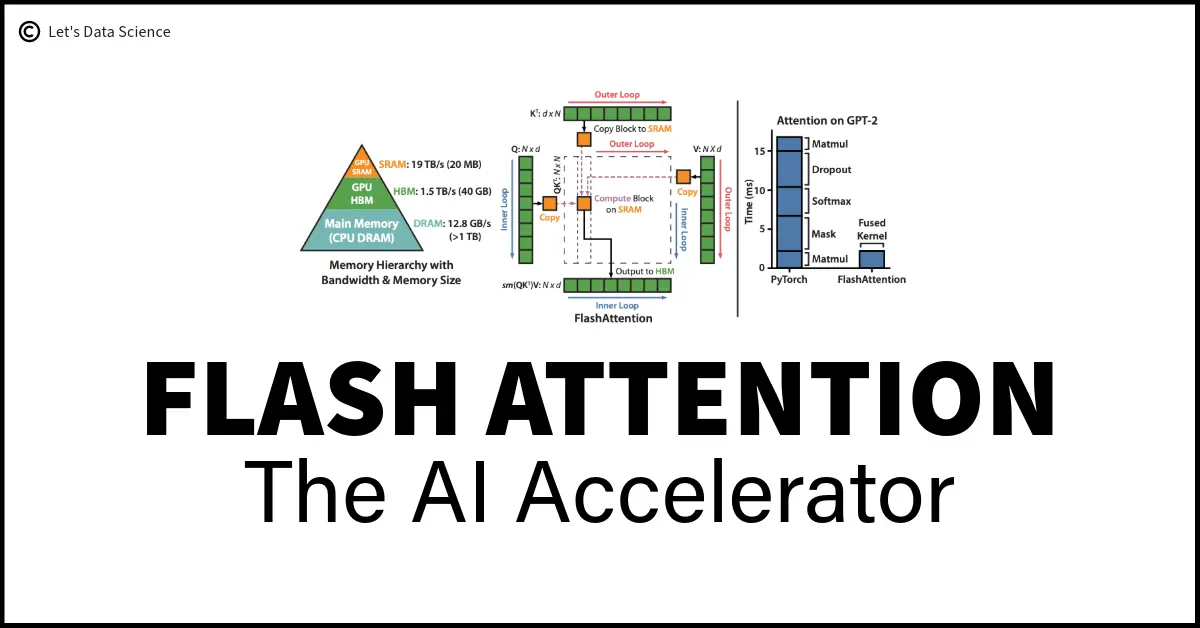
On the Left Side: Imagine trying to solve a huge puzzle but only having a small table. FlashAttention cleverly organizes pieces (data) to work on them a few at a time. It moves parts of the data (blocks of the K and V matrices) to a faster, but smaller, space (on-chip SRAM) for quick processing. Then, it does the same with other pieces of data (blocks of the Q matrix), ensuring everything is efficiently put together and sent back to the larger storage area (HBM). On the Right Side: When comparing FlashAttention's method to the usual way attention is calculated in AI models (like GPT-2) using PyTorch, FlashAttention is much faster. It avoids the slow process of dealing with a massive table of data all at once. Instead, it handles smaller parts efficiently, speeding up the process by 7.6 times. This image shows how FlashAttention makes AI models smarter by processing information faster and more efficiently, much like working on sections of a puzzle in a smaller, quicker workspace before putting it all together.
To address these challenges, Flash Attention emerges as a beacon of innovation. Here’s how it revolutionizes the attention mechanism landscape:
- Reduced Computational Complexity: Flash Attention optimizes the calculation of attention by introducing a novel, IO-aware algorithm. This algorithm smartly manages data reads and writes between different memory levels in a GPU, significantly reducing the computational load.
- Enhanced Memory Efficiency: By utilizing a technique called ’tiling,’ Flash Attention minimizes the memory accesses required for processing. This approach is akin to reading a book by efficiently skimming through sections you’re familiar with, focusing your attention only where it’s needed.
- Scalability: Perhaps the most significant advantage is Flash Attention’s ability to scale. It makes processing long sequences feasible, opening up new possibilities for AI models to understand and generate more complex and nuanced texts.
Real-World Example
Consider a platform like ChatGPT, which interacts with users in real-time, providing responses that are both relevant and contextually aware. Traditional attention mechanisms could limit its ability to quickly process long conversations or complex queries. Flash Attention, by reducing computational and memory demands, could enable a platform like ChatGPT to handle these tasks more efficiently, leading to faster, more accurate responses.
Understanding Flash Attention
In this section, we’re diving into the heart of Flash Attention, a groundbreaking technology that’s transforming how machines understand and process information. Imagine you’re at a bustling party, trying to focus on a conversation with a friend. Your brain naturally tunes out background noise, concentrating on the important sounds. Flash Attention works similarly but in the digital realm, helping computers focus on crucial information while processing data.
What is Flash Attention?
Flash Attention is a smart technique used by computers, especially in tasks involving language understanding, like reading this article or translating languages. It’s designed to be super quick and efficient, enabling computers to handle lots of information without getting “tired” or running out of “memory.”
Key Points:
- Fast Processing: Makes computers quicker at understanding and responding to language.
- Memory-Efficient: Allows computers to work with large amounts of text without using up all their memory.
- IO-Awareness: A clever trick that helps computers organize their “thoughts” more efficiently, reducing the time they need to “think.”
How Flash Attention Works
Imagine you’re doing a jigsaw puzzle. Instead of trying to fit every piece at once, you group them by color or edge pieces first. This method is quicker and less overwhelming. Flash Attention does something similar with information. It organizes and processes data in “chunks,” making it faster and less memory-intensive.
IO-awareness is like having a super-organized desk. Everything you need is within reach, so you spend less time searching for stuff. For computers, this means they can access and use data more efficiently, speeding up their work.

Key Benefits of Flash Attention
- Faster Processing Times:
- Imagine your computer can read and understand a novel as quickly as you flip through a picture book. That’s the speed we’re talking about!
- Reduced Memory Requirements:
- It’s like needing a smaller bookshelf but still keeping all your favorite books. Computers can handle more information without needing more space.
- Enhanced Model Capabilities:
- This is akin to learning new words from a book so you can have richer conversations. Computers can understand and generate more complex and nuanced responses.
Real-World Application Example
Consider ChatGPT or Google Bard. These platforms use similar advanced attention mechanisms to understand and generate human-like text. With Flash Attention, they could potentially process longer conversations or more complex questions much faster, making interactions smoother and more natural.
Comparison Table
To make it clearer, let’s look at a simple table comparing Traditional Attention with Flash Attention:
| Feature | Traditional Attention | Flash Attention |
|---|---|---|
| Speed | Slower | Much faster |
| Memory Usage | High | Low |
| Complexity Handling | Struggles with long sequences | Excels with long sequences |
| Real-World Application | Limited by processing speed and memory | Enhanced capabilities, better user experience |
Practical Example with Flash Attention
This section delves into a direct comparison between traditional attention mechanisms and Flash Attention, using a practical coding example. Our goal is to empirically demonstrate the efficiency gains in processing speed and potentially memory usage, by Flash Attention over the standard attention mechanism.
Introduction to the Case Study
We aim to explore Flash Attention’s impact on AI performance, specifically focusing on processing efficiency. We’ll use a controlled experiment setup to compare the processing times of traditional and Flash Attention mechanisms under identical conditions.
Objective
- To compare the processing speed of the standard attention mechanism with Flash Attention.
- To showcase the practical benefits of Flash Attention in enhancing AI model efficiency.
Setup
We simulate an attention mechanism operation on a set of randomly generated queries (q), keys (k), and values (v), representing typical inputs in transformer-based models like GPT-2. Our environment is a CUDA-enabled device, ensuring GPU acceleration for both methods.
Experiment Design
We measure the time taken to perform a scaled dot-product attention operation, first using a traditional approach and then with Flash Attention. Both methods are executed over a set number of trials to ensure statistical significance.
Python Code Snippet for Experiment
import time
import torch
import torch.nn.functional as F
# Define the experiment parameters
bz = 32 # Batch size
seq_len = 2048 # Sequence length
dims = 64 # Dimensions
n_heads = 8 # Number of heads
q = torch.randn(bz, n_heads, seq_len, dims, dtype=torch.float16).cuda()
k = torch.randn(bz, n_heads, seq_len, dims, dtype=torch.float16).cuda()
v = torch.randn(bz, n_heads, seq_len, dims, dtype=torch.float16).cuda()
dropout_rate = 0.2
num_trials = 10
# Standard Attention Computation
torch.cuda.synchronize()
start_time = time.time()
for _ in range(num_trials):
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
attn = F.dropout(attn, p=dropout_rate, training=True)
x = (attn @ v).transpose(1, 2)
torch.cuda.synchronize()
standard_duration = time.time() - start_time
print(f'Standard attention took {standard_duration:.4f} seconds for {num_trials} trials')
# Flash Attention Computation
with torch.backends.cuda.sdp_kernel(enable_flash=True):
torch.cuda.synchronize()
start_time = time.time()
for _ in range(num_trials):
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_rate)
torch.cuda.synchronize()
flash_duration = time.time() - start_time
print(f'Flash attention took {flash_duration:.4f} seconds for {num_trials} trials')
Python Code Execution and Results
Standard attention took 1.0446 seconds for 10 trials Flash attention took 0.3437 seconds for 10 trials
Google COLAB File:
Python Code Execution and Results
After conducting the experiment on Google Colab with a T4 GPU to compare the efficiency of the standard attention mechanism against Flash Attention, we observed remarkable results:
- Standard Attention: The traditional attention mechanism took 1.0446 seconds to complete the set of 10 trials.
- Flash Attention: Implementing Flash Attention significantly reduced the processing time to 0.3437 seconds for the same number of trials.
These findings underscore Flash Attention’s superiority in processing speed, showcasing a more than 3x improvement over the standard attention mechanism.
Analysis of Results
The experimental outcomes vividly highlight the efficiency gains provided by Flash Attention. This acceleration is especially significant considering the experiment’s straightforward nature, suggesting even greater potential efficiency improvements in more complex real-world applications. The dramatic reduction in processing time with Flash Attention could revolutionize AI model performance, making it an indispensable tool for developers and researchers seeking to optimize computational efficiency.
Discussion on Memory Efficiency
While our experiment focused on processing speed, Flash Attention’s design principles also aim to enhance memory efficiency. Although the current setup did not directly measure memory usage, Flash Attention’s methodology of optimizing data reads and writes suggests a substantial improvement in memory efficiency. This efficiency is crucial for processing large sequences or working with complex models, where traditional attention mechanisms often hit a bottleneck due to excessive memory demands.
Implications for AI Development
The results from this practical experiment reinforce the substantial value that Flash Attention brings to AI model development:
- Enhanced Processing Speeds: The ability to process information more rapidly opens up new possibilities for real-time AI applications, such as instant translation services, real-time content generation, and more dynamic interaction in AI-driven interfaces.
- Reduced Memory Usage: By minimizing memory requirements, Flash Attention enables the development of more sophisticated models that can handle extensive datasets with improved efficiency. This advancement is particularly relevant for fields requiring the analysis of large volumes of data, such as genomics, climate modeling, and complex simulations.
- Scalability: Flash Attention’s efficiency makes it possible to scale AI applications more effectively, supporting the development of systems that can learn from vast datasets without proportional increases in hardware demands.
Conclusion: The Future Brightened by Flash Attention
As we’ve journeyed through the innovative world of Flash Attention, it’s clear that this advancement is not just a step but a leap forward in the realm of Generative AI. Flash Attention simplifies complex processes, enabling faster, more efficient, and deeper understanding for AI models. It’s akin to giving a supercomputer the agility of a race car—vast capabilities, now moving at unprecedented speeds.
Recap of Flash Attention’s Impact
- Faster Processing Times: Like flipping pages in a book swiftly without missing the essence, Flash Attention streamlines AI’s data processing, making interactions with AI platforms, such as ChatGPT or Google Bard, significantly quicker.
- Reduced Memory Requirements: It ensures AI can remember and utilize more without the burden of a heavy memory load, much like having an efficient filing system that saves space yet stores everything important.
- Enhanced Model Capabilities: With Flash Attention, AI models can delve into more extensive and complex data, understanding nuances they previously couldn’t, broadening the horizon for applications in language translation, content creation, and beyond.
The Future of AI Development
Looking ahead, Flash Attention is set to redefine what’s possible in AI. Imagine AI systems that not only interact with human-like responsiveness but also offer insights derived from analyzing vast datasets in seconds. The potential for innovation in healthcare, education, and personalized technology is immense, promising advancements that were once relegated to the realm of science fiction.
Further Reading
Research Paper: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Medium Article: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness


