February 3, 2026
In late 2024, Elon Musk looked at the questions that AI companies use to measure how smart their models are. His verdict was blunt: "These are undergrad level. I want things that a world-class expert could do."
That conversation, with machine learning researcher Dan Hendrycks, sparked a global effort to create the hardest test ever designed for artificial intelligence. The result is Humanity's Last Exam, a collection of 2,500 questions so difficult that the world's most advanced AI systems are failing spectacularly.
As of February 3, 2026, the top-performing model, Google's Gemini 3 Pro Preview, scores just 37.52%. Most models hover below 30%. The exam has become a humbling benchmark for an industry that often speaks in terms of superintelligence and AGI. It turns out that when you actually test AI against the frontier of human knowledge, the machines still have a long way to go.
What Is Humanity's Last Exam?
Humanity's Last Exam (HLE) is a benchmark consisting of 2,500 expert-level questions spanning over 100 academic subjects. It was created by the Center for AI Safety (CAIS) and Scale AI, with contributions from nearly 1,000 subject-matter experts across more than 500 institutions in 50 countries.
The name is deliberately provocative. The creators call it "the final closed-ended academic benchmark of its kind", the idea being that once AI can pass this test, there may be nothing left to ask.
Unlike standard AI benchmarks that test general knowledge or undergraduate-level reasoning, HLE targets the absolute frontier of human expertise. The questions come from professors, researchers, and PhD holders who submitted problems from their own specialized domains, questions that would stump most humans, let alone machines.
The research was published in Nature in early 2025 and has since become one of the most closely watched metrics in AI development.
Why Was It Created?
The short answer: existing benchmarks got too easy.
The most popular AI evaluation, MMLU (Massive Multitask Language Understanding), tests models across 57 academic subjects. When it launched, top models scored around 40%. By late 2024, frontier models like Claude and GPT-4 were scoring above 90%.
"They're now crushed," Hendrycks told Reuters in September 2024, referring to traditional benchmarks after OpenAI's o1 model "destroyed the most popular reasoning benchmarks."
This created a measurement problem. If every new model aces the test, how do you tell which one is actually smarter? Benchmarks are supposed to reveal capability gaps, not produce participation trophies.
Stanford's HAI AI Index 2025 Annual Report cited Humanity's Last Exam as one of the "more challenging benchmarks" developed specifically because popular tests had reached "saturation."
 Click to expandSubject Distribution
Distribution of questions by subject in Humanity's Last Exam. Mathematics dominates at 41%, followed by Biology/Medicine (11%), Computer Science/AI (10%), and Physics (9%). Source: Humanity's Last Exam Research Paper (arXiv:2501.14249)
Click to expandSubject Distribution
Distribution of questions by subject in Humanity's Last Exam. Mathematics dominates at 41%, followed by Biology/Medicine (11%), Computer Science/AI (10%), and Physics (9%). Source: Humanity's Last Exam Research Paper (arXiv:2501.14249)
How Hard Are the Questions?
The questions on Humanity's Last Exam are not trivia. They require deep, specialized knowledge that typically takes years of graduate study to acquire.
Here are real examples from the exam:
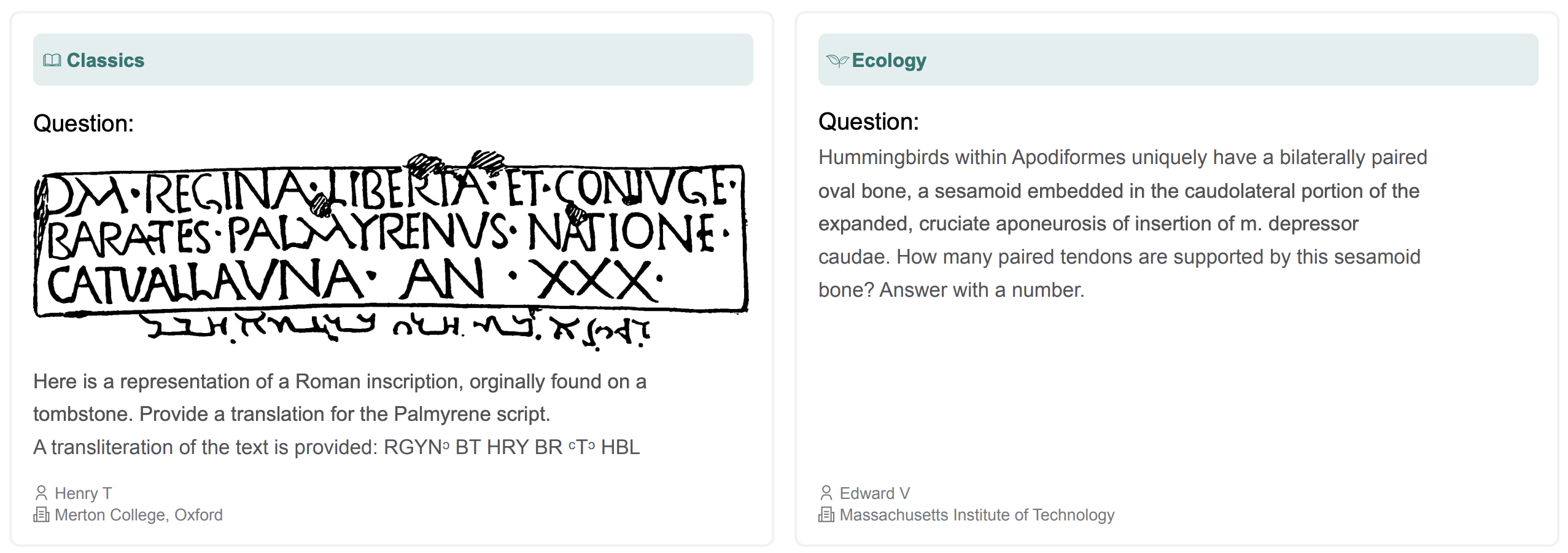 Click to expandClassics & Ecology: Translation of ancient Palmyrene script and specialized ornithology questions from Oxford and MIT contributors
Click to expandClassics & Ecology: Translation of ancient Palmyrene script and specialized ornithology questions from Oxford and MIT contributors
 Click to expandMathematics & CS: Category theory, natural cotransformations, and Markov chains on graph structures requiring graduate-level expertise
Click to expandMathematics & CS: Category theory, natural cotransformations, and Markov chains on graph structures requiring graduate-level expertise
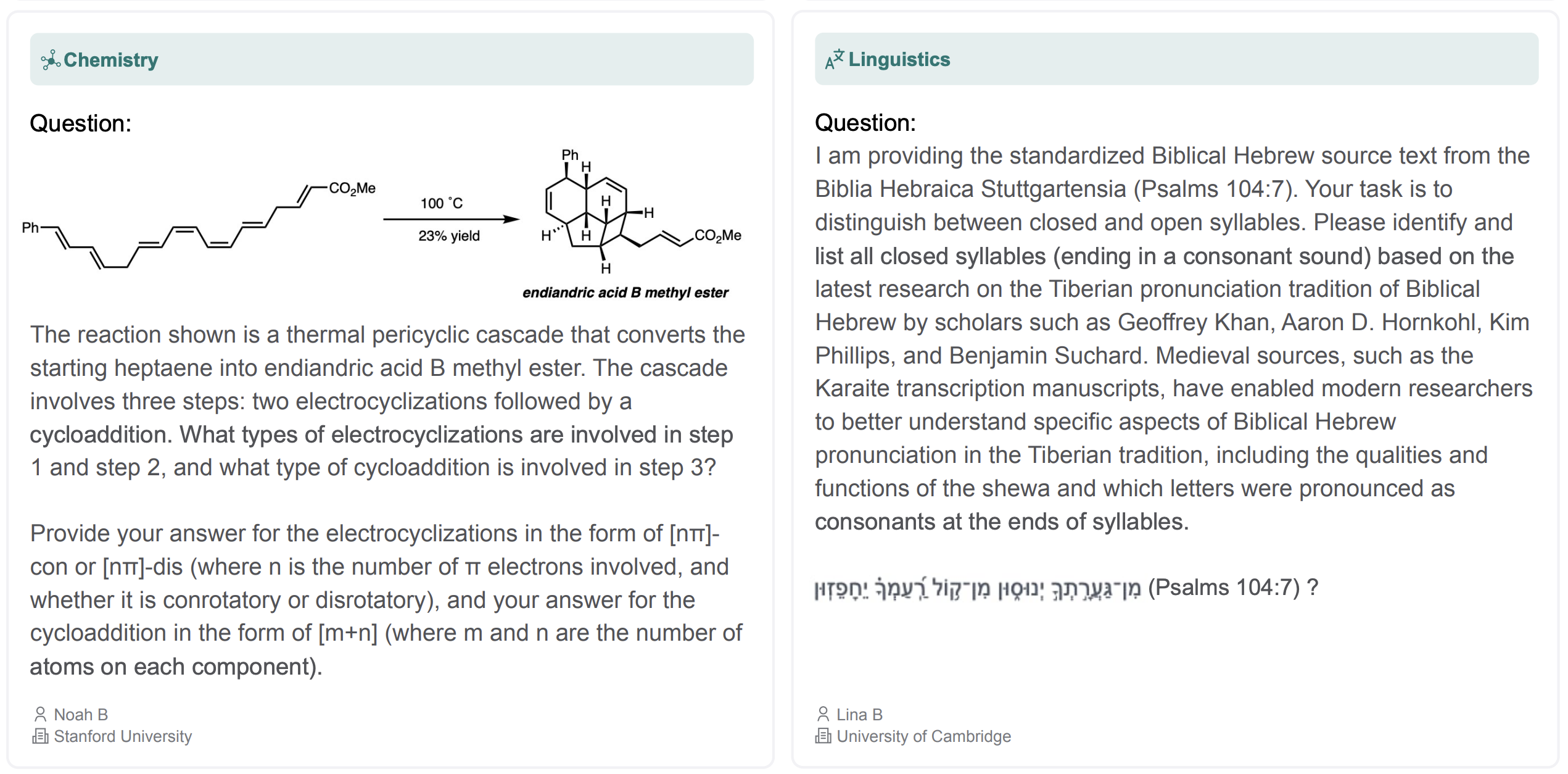 Click to expandChemistry & Linguistics: Thermal pericyclic cascades and Biblical Hebrew syllable analysis demanding deep domain expertise
Click to expandChemistry & Linguistics: Thermal pericyclic cascades and Biblical Hebrew syllable analysis demanding deep domain expertise
Source: Humanity's Last Exam Research Paper (arXiv:2501.14249)
The questions were designed with specific criteria:
- Precise and unambiguous with a single correct answer
- Non-searchable, you cannot Google your way to the answer
- Requires genuine expertise, not pattern matching or memorization
Contributors competed for a $500,000 prize pool: $5,000 for each of the top 50 questions and $500 for the next 500, along with optional co-authorship on the research paper.
The Leaderboard: How AI Models Are Performing
As of February 3, 2026, here is how the leading AI models score on Humanity's Last Exam:
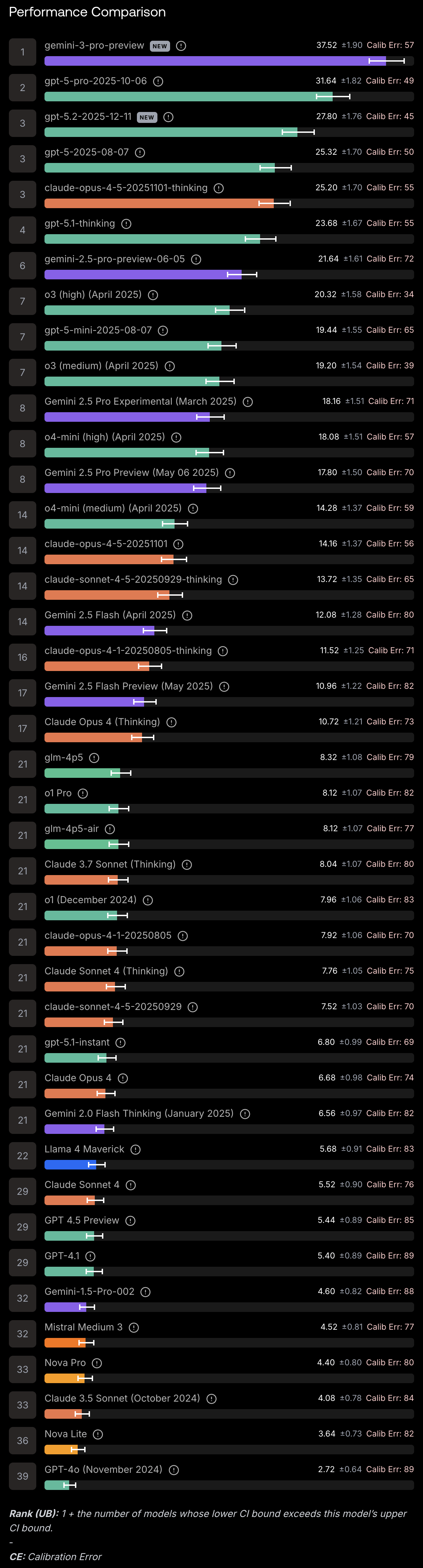 Click to expandHLE Leaderboard
Performance comparison of AI models on Humanity's Last Exam as of February 3, 2026. Gemini 3 Pro Preview leads at 37.52%, with most models showing high calibration errors indicating overconfidence. Source: Scale AI Leaderboard
Click to expandHLE Leaderboard
Performance comparison of AI models on Humanity's Last Exam as of February 3, 2026. Gemini 3 Pro Preview leads at 37.52%, with most models showing high calibration errors indicating overconfidence. Source: Scale AI Leaderboard
| Rank | Model | Score | Calibration Error |
|---|---|---|---|
| 1 | Gemini 3 Pro Preview | 37.52% | 57% |
| 2 | GPT-5 Pro (Oct 2025) | 31.64% | 49% |
| 3 | GPT-5.2 (Dec 2025) | 27.80% | 45% |
| 3 | Claude Opus 4.5 (Thinking) | 25.20% | 55% |
| 4 | GPT-5 (Aug 2025) | 25.32% | 50% |
| 4 | GPT-5.1 Thinking | 23.68% | 55% |
| 6 | Gemini 2.5 Pro Preview | 21.64% | 72% |
| 7 | O3 High (April 2025) | 20.32% | 34% |
| 7 | GPT-5 Mini | 19.44% | 65% |
| 7 | O3 Medium (April 2025) | 19.20% | 39% |
| ... | ... | ... | ... |
| 21 | Claude Sonnet 4 (Thinking) | 7.76% | 75% |
| 22 | Llama 4 Maverick | 5.68% | 83% |
| 29 | Claude Sonnet 4 | 5.52% | 76% |
| 33 | Claude 3.5 Sonnet (Oct 2024) | 4.08% | 84% |
| 39 | GPT-4o (Nov 2024) | 2.72% | 89% |
For context, when the benchmark first launched in early 2025:
- GPT-4o scored 2.7%
- Claude 3.5 Sonnet scored 4.1%
- OpenAI's o1 scored 8%
In roughly one year, scores have climbed from single digits to the high 30s. The pace of improvement is remarkable, but the models are still failing nearly two-thirds of questions.
The Calibration Problem: AI Doesn't Know What It Doesn't Know
One of the most striking findings from HLE isn't the low accuracy, it's the calibration error.
Calibration measures whether a model's confidence matches its actual performance. If a model says it's 90% sure of an answer, it should be correct about 90% of the time.
On Humanity's Last Exam, models show calibration errors ranging from 34%** to 89%**. This means AI systems are systematically overconfident. They express high certainty on answers they get wrong.
The Scale AI leaderboard describes this as evidence of "widespread confabulation", the models are confidently making things up.
The O3 models show the lowest calibration errors (34-39%), suggesting better self-awareness of their limitations. Meanwhile, GPT-4o shows an 89% calibration error, nearly the worst possible score.
This has significant implications for real-world AI deployment. If a model doesn't know what it doesn't know, it becomes unreliable in high-stakes domains like medicine, law, or scientific research.
The Controversy: Are 30% of the Answers Wrong?
In July 2025, AI research lab FutureHouse published a critical analysis suggesting that approximately 29%** of the chemistry and biology questions** in HLE have incorrect or misleading answers.
FutureHouse used their AI agent Crow (built on PaperQA2) to cross-reference HLE answers against peer-reviewed literature. They found that 53.3% of the rationales provided for chemistry and biology questions directly conflicted with published evidence.
One example they highlighted: A question asked about the rarest noble gas on Earth as of 2002. The HLE answer was "Oganesson", a synthetic element that existed for only a few milliseconds in a Russian nuclear reactor. Only five atoms have ever been created, and some scientists argue it's not technically a "noble gas" or even a "gas" at all.
Scale AI's Response
Scale AI, which co-created the benchmark, conducted their own follow-up analysis and estimated the error rate at 18%, not 29%. They revised their preprint to address the concerns.
In response, FutureHouse released a curated subset called "HLE Bio/Chem Gold" on HuggingFace, containing only the questions they verified as accurate.
The controversy highlights a broader challenge: creating expert-level questions at scale is hard. Even with nearly 1,000 PhD-level contributors, errors slip through.
What Does It Mean When AI Passes 50%?
Dan Hendrycks has said that once models start scoring over 50%, "it's safe to say humans have met their match in this regard."
But the HLE team is careful to clarify what that would, and would not, mean.
What 50%+ accuracy would demonstrate:
- Expert-level performance on closed-ended, verifiable questions
- Access to latest scientific knowledge
- Strong reasoning within structured academic problems
What it would NOT demonstrate:
- Autonomous research capabilities
- Creative problem-solving
- "Artificial General Intelligence" (AGI)
As the researchers write: "HLE tests structured academic problems rather than open-ended research or creative problem-solving abilities, making it a focused measure of technical knowledge and reasoning."
In other words, acing the exam wouldn't mean AI can do science. It would mean AI can answer test questions about science.
The Policy Implications
Despite its limitations, Humanity's Last Exam has become influential in AI governance discussions.
Policymakers are using specific score thresholds as potential triggers for oversight. The EU AI Act and the UK AI Safety Institute have both referenced benchmark-based evaluation as part of their frameworks for assessing frontier AI capabilities.
If models cross 50% on HLE, it could prompt:
- Mandatory safety evaluations before deployment
- Additional transparency requirements for AI labs
- Escalated scrutiny from regulators
The benchmark provides something rare in AI policy: an objective, quantifiable measure that everyone can reference. Whether it's the right measure is a separate debate.
The Bigger Picture: What HLE Reveals About AI
Humanity's Last Exam has become a reality check for an industry prone to hype.
When ChatGPT launched in late 2022, many predicted that superhuman AI was imminent. The models seemed to know everything, converse fluently, and reason through complex problems. But HLE shows that "knowing everything" and "understanding deeply" are very different things.
The exam also reveals the gap between benchmark performance and real-world capability. A model that scores 90% on MMLU might still fail basic questions from a biology PhD's specialized subfield. Intelligence, it turns out, is not a single number.
As the researchers note: "Intelligence is multi-dimensional, and many aspects, creativity, consciousness, empathy, elude any standardized test."
Humanity's Last Exam may be the final academic benchmark we need. But it's far from the final measure of machine intelligence.
Who Created It?
Lead Organizers
- Dan Hendrycks, Director, Center for AI Safety; Safety Adviser to xAI
- Long Phan, Lead organizer
- Alice Gatti, Lead organizer
- Ziwen Han, Lead organizer
- Nathaniel Li, Lead organizer
Senior Advisors
- Summer Yue, Scale AI
- Alexandr Wang, CEO, Scale AI
The Contributors
Nearly 1,000 subject-matter experts from institutions including MIT, UC Berkeley, Stanford, Cambridge, University of São Paulo, Queen Mary University of London, and hundreds of others across 50 countries. Most are professors, researchers, or hold graduate degrees in their fields.
Frequently Asked Questions
What is HLE?
Humanity's Last Exam (HLE) is a benchmark of 2,500 expert-level questions across 100+ subjects, created by the Center for AI Safety and Scale AI to test the limits of AI capabilities. It was published in Nature in 2025.
Why is it called "Humanity's Last Exam"?
The name suggests it may be the final closed-ended academic test needed for AI. Once models can pass it, there may be no harder standardized exam to give them.
What's the highest score so far?
As of February 3, 2026, Google's Gemini 3 Pro Preview leads with 37.52% accuracy, followed by GPT-5 Pro at 31.64%.
Does passing the exam mean AI has achieved AGI?
No. The creators explicitly state that even 100% accuracy would not indicate AGI. The test measures structured academic knowledge, not autonomous research, creativity, or general intelligence.
Are there errors in the exam?
FutureHouse found that approximately 29% of chemistry/biology questions may have incorrect answers. Scale AI estimates the error rate at 18%. A verified subset called "HLE Bio/Chem Gold" is available on HuggingFace.
Where can I see the questions?
A public dataset is available at agi.safe.ai. A private held-out test set is used to prevent overfitting.
Key Resources
| Resource | Link |
|---|---|
| Official Website | agi.safe.ai |
| Scale AI Leaderboard | scale.com/leaderboard/humanitys_last_exam |
| Research Paper (arXiv) | arxiv.org/abs/2501.14249 |
| Nature Publication | nature.com/articles/s41586-025-09962-4 |
| FutureHouse Analysis | futurehouse.org/research-announcements/hle-exam |
| Center for AI Safety | safe.ai |
Sources
This article draws from reporting and research by Nature, Scale AI, Center for AI Safety, FutureHouse, Fortune, The Conversation, Wikipedia, DataCamp, Artificial Analysis, and Stanford HAI AI Index 2025.